使用者回報問題的時候,已經太晚了。監控的目標是讓你在事故之前看到趨勢、在事故當下快速定位、在事故後有資料做復盤。沒有數據,你做的所有判斷都只是猜測。
先講結論
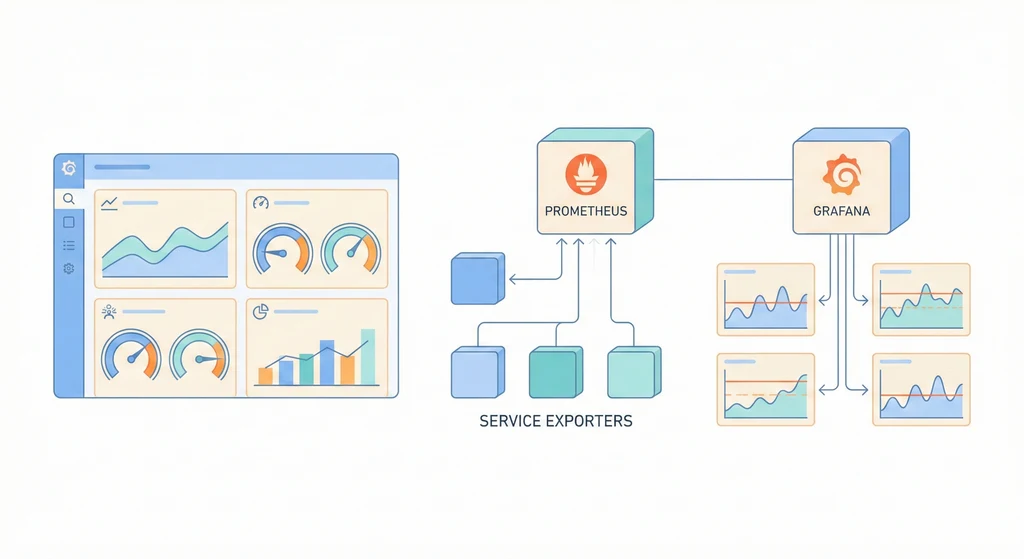
Prometheus pull metrics、Grafana 做儀表板、Alertmanager 發告警。這三件套是監控的基座。每個服務暴露 /metrics,exporter 補齊系統指標,然後你只需要會寫幾行 PromQL 就能看懂系統狀態。
Pull Model:為什麼 Prometheus 主動拉
Prometheus 不等你推資料過來,它主動去抓。好處是 target 掛了 = scrape 失敗 = 你馬上知道。不用在 target 設定 Prometheus 位址,新增服務只要加一行 scrape config。
唯一的缺點:短生命週期的 job(跑完就消失的 cron)需要用 Pushgateway 推指標。但大部分場景都是 pull 就夠了。
指標分類:你要先搞清楚在查什麼
- Counter:只增不減。例如
requests_total。要看速率就用rate()。 - Gauge:上下浮動。例如
memory_usage_bytes。直接看數值。 - Histogram:延遲分佈。例如
http_request_duration_seconds_bucket。用histogram_quantile()算 P95。
用 counter 的方式去看 gauge(或反過來)會得到毫無意義的結果。先分清楚類型。
Exporter 生態:Prometheus 不懂你的服務
Prometheus 本身不知道你的 CPU 用量或 DB 連線數。靠 exporter 把指標轉成 /metrics 端點:
node_exporter:Host(CPU、RAM、Disk)cadvisor:Container 資源用量postgres_exporter:DB 指標nginx_exporter:入口指標
最常用的 PromQL
# CPU 使用率(%)
100 - (avg by(instance) (rate(node_cpu_seconds_total{mode="idle"}[5m])) * 100)
# P95 延遲
histogram_quantile(0.95, sum(rate(http_request_duration_seconds_bucket[5m])) by (le))
# 5 分鐘錯誤率
sum(rate(http_requests_total{status=~"5.."}[5m])) / sum(rate(http_requests_total[5m]))這三個 query 能回答 80% 的「系統現在怎樣」的問題。把它們放在 Grafana overview dashboard 上,一眼就能判斷要不要緊張。
告警規則基線
groups:
- name: host
rules:
- alert: HighCPU
expr: 100 - (avg by(instance) (rate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) > 85
for: 5m
labels:
severity: warning
annotations:
summary: "CPU usage > 85%"
- alert: DiskSpaceLow
expr: (node_filesystem_avail_bytes{mountpoint="/"} / node_filesystem_size_bytes{mountpoint="/"}) * 100 < 20
for: 5m
labels:
severity: critical
- name: app
rules:
- alert: ApiErrorRateHigh
expr: sum(rate(http_requests_total{status=~"5.."}[5m])) / sum(rate(http_requests_total[5m])) > 0.02
for: 5m
labels:
severity: critical還有一個最重要但最容易忘記的告警:up == 0。target 掛了沒人知道,等於你的監控也掛了但你不知道。
Dashboard 分層:不要全部塞一頁
- Overview:一眼看系統狀況(CPU、RAM、錯誤率、延遲)
- Service:單一服務的詳細指標
- Debug:事故排查用的深度圖表
把所有東西塞在同一頁的 dashboard,等於什麼都看不到。核心 dashboard 要版本控管(JSON export 進 Git),別讓某個人手動調了一下然後沒人知道改了什麼。
常見踩坑
Prometheus 磁碟爆掉:指標太多 + 沒設 retention。加上 --storage.tsdb.retention.time=30d 和 --storage.tsdb.retention.size=10GB。
指標數量爆炸:有人把 user_id 當 label,結果 cardinality 爆炸。label 只放低 cardinality 的值(service、env、status code),不要放 user_id 或 request_id。
監控就像健康檢查。你不會等到倒下才去看醫生——但很多系統就是這樣運作的。