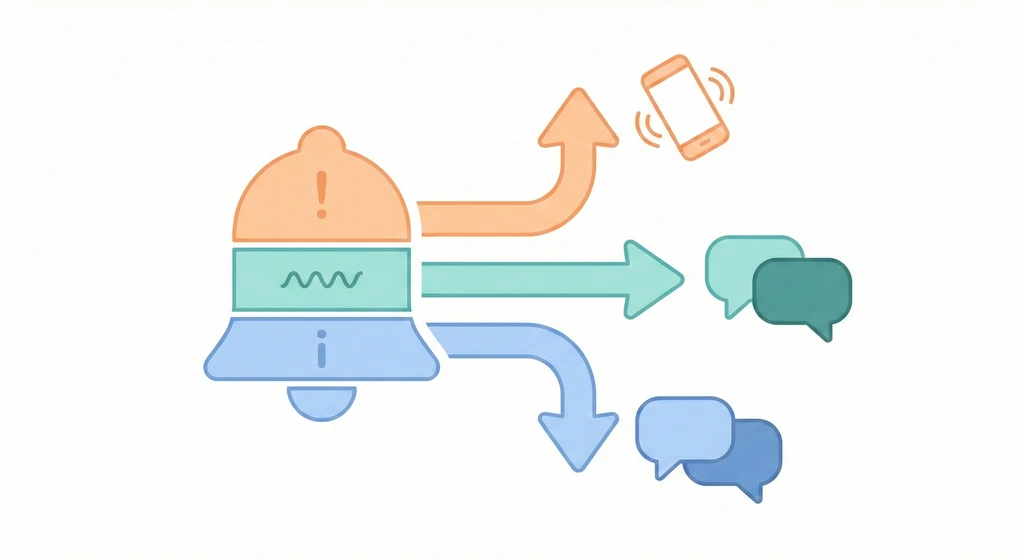
告警的目標不是發通知。如果你的 Slack channel 每天有 50 則告警,沒有人會認真看任何一則。告警的目標是:讓對的人在對的時間收到對的訊息,然後知道下一步要做什麼。
先講結論
告警要分級(Critical / Warning / Info)、分流(不同嚴重度走不同通知管道)、每個告警要有 Runbook(出事時照著做)。做不到這三件事,你的告警系統只是一個「製造噪音的機器」。
分級:不是所有告警都要打電話
Critical:直接影響用戶。5-10 分鐘內要有人介入。走 PagerDuty / 電話。
Warning:趨勢異常。30-60 分鐘內處理。走 Slack / Discord。
Info:低優先。只記錄或每日摘要 email。
很多團隊只有一個等級:全部都是 Critical。結果值班的人每天被叫醒三次,半年後沒有人再理告警了。這就是著名的「狼來了」系統架構。
Alertmanager 路由
route:
group_by: ['alertname', 'service']
group_wait: 30s
group_interval: 5m
repeat_interval: 2h
receiver: 'default'
routes:
- match:
severity: critical
receiver: 'pager'
- match:
severity: warning
receiver: 'chat'
- match:
severity: info
receiver: 'digest'
receivers:
- name: 'pager'
webhook_configs:
- url: http://pagerduty-webhook
- name: 'chat'
slack_configs:
- channel: '#alerts'
send_resolved: true
- name: 'digest'
email_configs:
- to: ops@example.comsend_resolved: true 很重要——問題解決的通知跟問題發生的通知一樣重要。不然你會一直擔心那個問題到底解了沒有。
Runbook:告警裡面要告訴你怎麼做
收到告警然後呢?如果值班的人要花 20 分鐘去 Google「CPU 高怎麼處理」,那你的告警設計就失敗了。
每個告警都應該連結到一份 Runbook:
# [Alert] HighCPU
## 症狀
- CPU > 85% 持續 5 分鐘
## 可能原因
- 突增流量
- 新版造成效能退化
- Background job 失控
## 檢查清單
1. Grafana 檢查 CPU 曲線
2. 檢查最近 30 分鐘有沒有 deploy
3. 看 top process / container
## 解法
- 限流或降級
- 回滾上一版ChatOps:告警 → 處理 → 回報的閉環
- 告警進 Slack channel
- 值班的人回覆
ACK表示正在處理 - 貼出 runbook 連結
- 處理過程中更新狀態
- 解決後寫 postmortem
不要讓告警變成「發完就沒人管」。告警是一個流程的開始,不是結束。
告警設計原則
只告警「需要人介入」的事情。CPU 短暫飆到 90% 然後自己降下來?那不需要告警。用 for: 5m 避免短期抖動觸發誤報。
Warning 不要打電話。你可以讓團隊容忍偶爾漏看一則 warning,但不能讓值班的人因為 warning 在凌晨三點被叫醒。
- alert: ApiErrorRateHigh
expr: sum(rate(http_requests_total{status=~"5.."}[5m])) / sum(rate(http_requests_total[5m])) > 0.02
for: 5m
labels:
severity: critical
- alert: HighLatencyP95
expr: histogram_quantile(0.95, sum(rate(http_request_duration_seconds_bucket[5m])) by (le)) > 1.5
for: 10m
labels:
severity: warning最常見的錯誤
閾值太低:每天幾十封告警,團隊直接無視。定期 review 閾值,如果一個告警一個月觸發 50 次但都不需要處理,要嘛調高閾值,要嘛刪掉它。
沒有 postmortem:每次事故都從頭想。Postmortem 不是為了究責,是為了不要踩同一個坑。
好的告警系統就像好的消防隊——不是每次聽到動靜都出動,而是在真正著火的時候,5 分鐘內到場,而且知道該拿什麼工具。