資料庫是所有服務的核心依賴。你的 API 可以掛、前端可以壞、CI 可以爆——但 DB 裡的資料不見了,那就是真的完了。即使只是單節點,也必須有「可恢復」的策略,而不是「先跑起來再說」。
先講結論
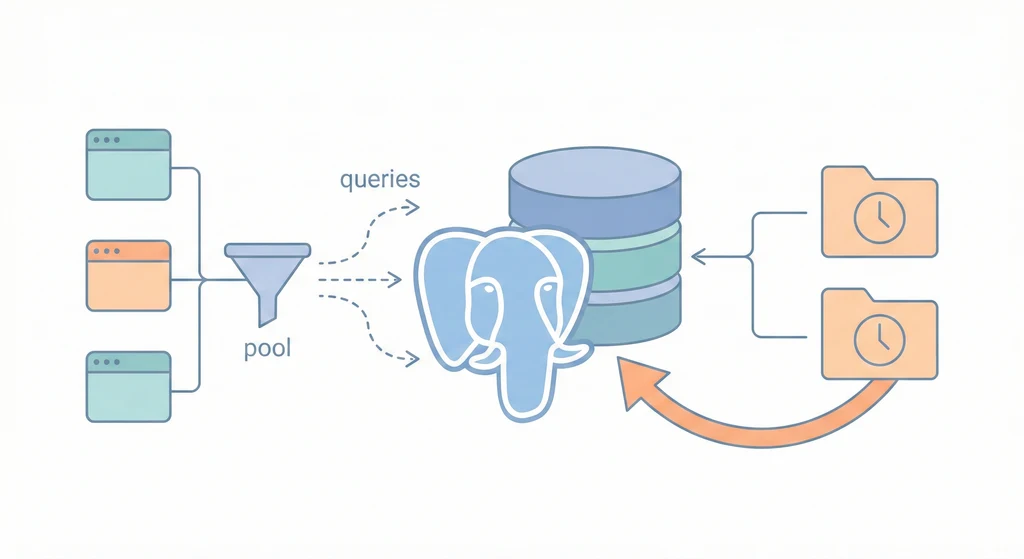
單節點 PostgreSQL 的生存基線:PgBouncer 控制連線數、pg_dump 做每日備份並上傳、效能參數調過預設值、每季做還原演練。四件事,哪一件沒做都是在賭運氣。
PgBouncer:為什麼你需要連線池
PostgreSQL 是 process-per-connection 架構。每來一個連線就 fork 一個 process。連線太多就吃光記憶體,然後新連線全部被拒。
PgBouncer 讓應用端以為有 200 個連線,但實際連到 PostgreSQL 的可能只有 50 個。pool_mode = transaction 最常用——transaction 結束就把連線還回 pool。
services:
postgres:
image: postgres:16-alpine
restart: unless-stopped
environment:
POSTGRES_DB: myapp
POSTGRES_USER: myapp
POSTGRES_PASSWORD: ${DB_PASSWORD}
volumes:
- pg-data:/var/lib/postgresql/data
- ./postgresql.conf:/etc/postgresql/postgresql.conf
command: postgres -c config_file=/etc/postgresql/postgresql.conf
ports:
- "127.0.0.1:5432:5432"
pgbouncer:
image: edoburu/pgbouncer:latest
restart: unless-stopped
environment:
DATABASE_URL: postgresql://myapp:${DB_PASSWORD}@postgres:5432/myapp
POOL_MODE: transaction
MAX_CLIENT_CONN: 200
DEFAULT_POOL_SIZE: 50
ports:
- "127.0.0.1:6432:6432"
depends_on:
postgres:
condition: service_healthy
volumes:
pg-data:所有應用只連 PgBouncer(port 6432),不要直連 PostgreSQL。我見過有人直連跑到 100 個連線然後整個 DB 卡死的。
效能調校:預設值是給「不出事就好」用的
PostgreSQL 預設設定非常保守。8GB RAM 的機器用預設值,shared_buffers 只有 128MB,等於你有一棟房子但只用了一個房間。
# 8GB RAM 建議基線
shared_buffers = 2GB
work_mem = 128MB
maintenance_work_mem = 512MB
effective_cache_size = 6GB
# 慢查詢紀錄(超過 1 秒的 query 都記下來)
log_min_duration_statement = 1000
# 統計模組
shared_preload_libraries = 'pg_stat_statements'pg_stat_statements 是你最好的朋友。它會記錄每個 query 的平均執行時間和呼叫次數,讓你知道哪個 query 最慢、最常被呼叫。
備份:只備份不還原等於沒備份
#!/bin/bash
set -euo pipefail
DATE=$(date +%Y-%m-%d_%H%M)
BACKUP_FILE="/tmp/pg-backups/myapp_${DATE}.sql.gz"
PGPASSWORD="$DB_PASSWORD" pg_dump \
-h localhost -U myapp -d myapp \
-Fc --no-owner --no-privileges \
| gzip > "$BACKUP_FILE"
# 上傳到 MinIO
mc cp "$BACKUP_FILE" myminio/db-backups/$(date +%Y/%m)/
rm -f "$BACKUP_FILE"# crontab - 每天 03:00
0 3 * * * /opt/scripts/backup-postgresql.sh >> /var/log/pg-backup.log 2>&1重點來了:你有真的跑過還原嗎?
# 還原流程
mc cp myminio/db-backups/2024/09/myapp_2024-09-14_0300.sql.gz /tmp/
gunzip /tmp/myapp_2024-09-14_0300.sql.gz
PGPASSWORD="$DB_PASSWORD" pg_restore \
-h localhost -U myapp -d myapp_restore \
--clean --create \
/tmp/myapp_2024-09-14_0300.sql
# 驗證
psql -h localhost -U myapp -d myapp_restore -c "SELECT count(*) FROM users;"每季做一次還原演練。設 KPI:還原時間 < 2 小時。第一次演練的時候,你會發現很多「以為沒問題」的地方其實有問題。
最常炸掉的三件事
連線爆掉:沒用 PgBouncer + max_connections 太低。突然流量一大,新連線全部被拒。
WAL 爆滿:磁碟滿了,DB 直接起不來。設定 max_wal_size 並監控 disk usage。
備份沒驗證:天天都有跑備份,但從來沒還原過。真正出事才發現備份檔一直是壞的,或者還原腳本有 bug。那天你會非常懷念「每季演練」這件你一直覺得浪費時間的事。
資料庫就像心臟。平常你不會注意到它在跳,但它一停——所有東西都停了。