「我們應該用 MongoDB 還是 PostgreSQL?」——這個問題問錯了。正確的問題是:「我們的資料長什麼樣、怎麼被查詢、一致性需求到什麼程度?」
先講結論
大部分產品從 PostgreSQL 起步就對了。等到需要全文搜尋加 Elasticsearch,需要快取加 Redis,需要分析加 ClickHouse。一個產品通常不是「單一資料庫」,而是多個特化工具各司其職。選型的關鍵不是「哪個最好」,而是「每個選擇的代價是什麼」。
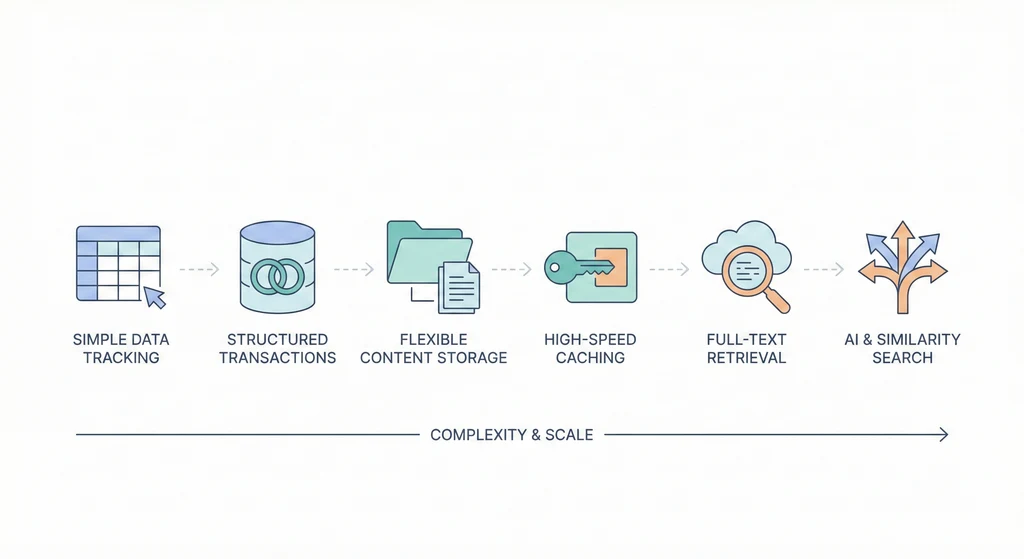
資料庫家族快速導覽
RDBMS(PostgreSQL / MySQL)——強一致性、ACID、擅長交易型應用。你八成的業務邏輯放這裡就夠了。
Key-Value(Redis / DynamoDB)——極快、結構簡單。適合快取、Session、排行榜。但它不是你的主資料庫。
Document(MongoDB)——Schema 彈性高,適合結構不固定的內容。但彈性的代價是治理成本——半年後你的 collection 裡有五種不同的結構,沒有人知道哪個是對的。
Column Store(ClickHouse / BigQuery)——為分析查詢而生。OLTP 別用它,OLAP 它很快。
Search Engine(Elasticsearch)——全文檢索、日誌分析、聚合查詢。但拜託不要拿它當主資料庫。
選型的四個問題
在決定用什麼之前,先回答:
- 資料結構會不會變? 會經常變 → Document 可能適合。結構穩定 → RDBMS 更安全。
- 一致性需求到什麼程度? 銀行轉帳不能最終一致。社群按讚數晚個幾秒更新沒關係。
- 讀寫比例如何? 讀多寫少可以靠 cache + replica。寫多讀少要考慮寫入效能。
- 查詢模式可預測嗎? 查詢模式固定 → RDBMS 的索引設計很有效。查詢模式千變萬化 → 可能需要搜尋引擎。
典型的混合架構長這樣
flowchart LR App[App Service] --> RDB[PostgreSQL] App --> Cache[Redis] App --> Search[Elasticsearch] RDB --> ETL[ETL Pipeline] ETL --> DW[Data Warehouse]
PostgreSQL 是你的 source of truth,Redis 幫你扛熱點讀取,Elasticsearch 讓搜尋功能飛快,Data Warehouse 處理報表跟分析。
重點是:Cache 跟 Search 不是主資料來源。主資料永遠在 RDBMS 裡。資料流的方向是 RDBMS → 其他系統,不是反過來。
常見反模式:用錯工具的下場
用 MongoDB 做交易——沒有 ACID 的保證,你的訂單系統遲早會出現「錢扣了但訂單沒建」的奇怪狀態。
用 Redis 當永久資料庫——Redis 是快取,記憶體滿了就開始丟資料。我見過把使用者 session 放 Redis 但沒做持久化,Redis 重啟後所有人被登出。
用 Elasticsearch 當主資料庫——ES 的寫入是 near-realtime,不是即時。寫完馬上查可能查不到。而且 ES 沒有 transaction。
為了「未來擴展性」一開始就分庫分表——你的 DAU 才一千,分什麼庫?先把一個 PostgreSQL 跑到極限再說。分庫分表是最後手段,不是起手式。
什麼時候該拆?
分庫分表的觸發條件:
- 單表達到千萬級以上且查詢變慢
- 單機 IOPS 接近上限
- 備份時間長到影響 RPO
- 不同業務的 SLA 差異很大
如果你還沒碰到這些問題,就不需要拆。過早最佳化是萬惡之源,Dennis Ritchie 說的,不是我。
延伸閱讀
- Designing Data-Intensive Applications
- PostgreSQL / MySQL 官方文件
- Elasticsearch Architecture Guide
資料庫選型最大的陷阱不是「選錯」,而是「選了之後不願意承認選錯」。當你發現自己在用大量 workaround 來彌補工具的不足時,也許該認真想想要不要遷移了。