你的客服 chatbot 回答公司政策時自信地瞎掰?RAG 可以治它。
先講結論
RAG(Retrieval-Augmented Generation)用一句話講就是:
回答問題之前,先去查資料。
就像考試的時候可以帶小抄——LLM 本來只靠自己「記住」的東西回答,現在你讓它看著資料回答。結果就是:回答更準確,還能告訴你「我是根據哪份文件說的」。
LLM 的三個致命傷
你有沒有遇過這種情況:問 ChatGPT「我們公司的退貨政策是什麼?」,它一本正經地回你「一般來說,退貨期限為 30 天」——但你們公司明明是 14 個工作天?
這就是 LLM 的三個致命傷:
1. 知識有截止日期 每個模型的訓練資料都有截止日。之後發生的事它完全不知道,但它不會說「我不知道」,它會猜。
2. 不認識你的資料 你的 Confluence、內部文件、客戶資料——LLM 一概不知。它只知道訓練時看過的公開網路資料。
3. 會自信地胡說八道 就是上一篇聊過的 Hallucination。不知道答案的時候,它會編一個看起來合理的答案。
RAG 一次解決這三個問題:讓它查你的資料庫再回答。查到就據實以告,查不到就說「我不知道」。
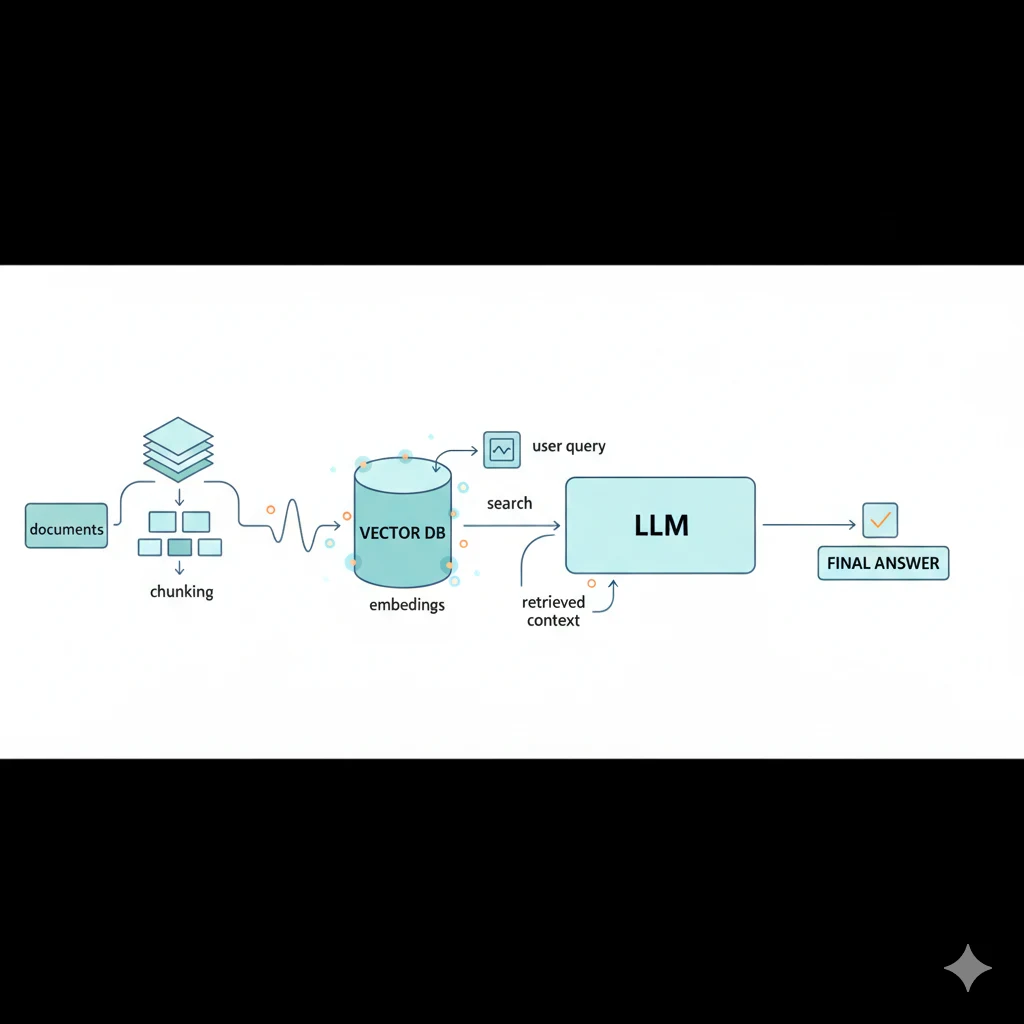
RAG 的架構其實很簡單
整個系統分兩個階段:
階段一:建索引(離線做一次)
你的文件(PDF、Markdown、HTML...)
→ 切成小段(Chunking)
→ 每段轉成向量(Embedding)
→ 存進向量資料庫(Vector DB)
階段二:回答問題(每次查詢都跑)
使用者問題
→ 問題也轉成向量
→ 在 Vector DB 裡找最相似的段落
→ 把問題 + 找到的段落一起丟給 LLM
→ LLM 根據段落內容回答
就這樣。沒有什麼神秘的。
核心概念就是:不改模型,只改模型看到的資料。LLM 還是同一個 LLM,但每次回答前你先幫它找好參考資料。
RAG vs Fine-tuning:什麼時候用哪個?
上一篇系列聊過 Fine-tuning vs RAG,這邊再從實務角度比一次:
| RAG | Fine-tuning | |
|---|---|---|
| 成本 | 低(Vector DB + Embedding API) | 高(GPU 訓練) |
| 更新知識 | 秒級(改文件就好) | 天級(重新訓練) |
| 來源追溯 | 可以引用原文 | 不行 |
| 幻覺控制 | 好(有來源可驗證) | 普通 |
| 你需要改的是… | 模型知道什麼 | 模型怎麼說話 |
經驗法則:
- 要讓 AI 知道你的資料 → RAG
- 要讓 AI 用你的語氣說話 → Fine-tuning
- 兩個都要 → RAG + 好好寫 system prompt(通常就夠了)
我自己做 ClawdBot 的時候,一開始也考慮過 fine-tune。後來發現 RAG 接上 workspace 的文件 + 寫好 system prompt,效果就已經很夠了。Fine-tune 的那些錢省下來,拿去付 API 帳單綽綽有餘。
一個最小可行的 RAG
不需要什麼 Milvus 集群或 Kubernetes,最簡單的 RAG 長這樣:
from openai import OpenAI
import chromadb
client = OpenAI()
db = chromadb.PersistentClient(path="./my_rag_db")
collection = db.get_or_create_collection("docs")
# 1. 塞文件進去(只做一次)
collection.add(
documents=["退貨期限為 14 個工作天", "運費由買方負擔"],
ids=["policy-1", "policy-2"],
)
# 2. 查詢 + 回答
results = collection.query(query_texts=["退貨期限多久?"], n_results=2)
context = "\n".join(results["documents"][0])
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "根據以下資料回答,資料中沒有的就說不知道。"},
{"role": "user", "content": f"資料:{context}\n\n問題:退貨期限多久?"},
],
)
print(response.choices[0].message.content)
# → "根據資料,退貨期限為 14 個工作天。"20 行搞定。先跑起來,再慢慢調。完美主義是 side project 的殺手。
下一篇
概念搞懂了,但魔鬼在細節——文件怎麼切?向量怎麼存?資料庫怎麼選?
RAG 就是給 AI 一本小抄。差別是這本小抄可以隨時更新,而且 AI 讀得比你快。