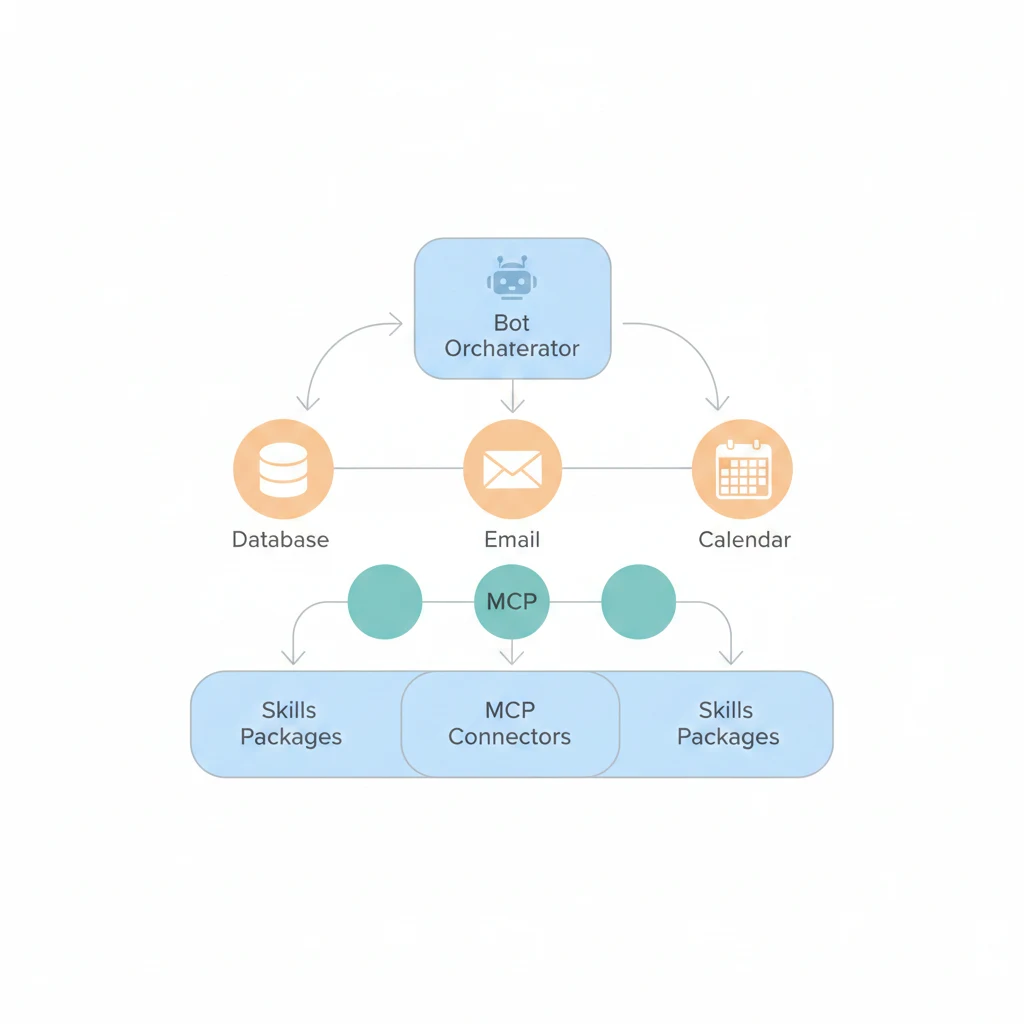
先講結論
AI 工具生態分三層:
Layer 1:Chat UI(ChatGPT 網頁)→ 你手動問,它手動答
Layer 2:Skills + MCP → AI 有了技能和對外接口
Layer 3:Bot / Agent → AI 自己跑,你不用盯
大部分人卡在 Layer 1。這篇教你怎麼跨到 Layer 2——用 Skills 教 AI 做事、用 MCP 讓 AI 接上外部系統。Layer 3 的 Bot 建置比較複雜,我另外寫了一篇 [[ai/07-2-building-ai-bot|[ai/07-2] 自建 AI Bot 實戰]]。
三個知識點:Skills 是什麼、MCP 是什麼、什麼情境該用哪個。
「會用 ChatGPT」跟「有 AI 工具鏈」差多遠?
你每天打開 ChatGPT 問問題,覺得自己很 AI,對吧?
這就像你會用計算機按加減乘除,然後跟人說「我有一套自動記帳系統」。嗯,差不多就是這麼離譜。
真正的 AI 工具鏈是:AI 自己讀 Notion、自己回 Discord、自己跑排程。你睡覺的時候它在幫你整理 email 摘要。你是老闆,不是操作員。
那怎麼從操作員變老闆?先從教 AI 做事開始。
Skills:給 AI 一份「新人入職指南」
這東西到底是什麼
想像你請了一個超聰明但什麼都不知道的新人。你會怎麼做?寫一份文件給他,告訴他任務是什麼、步驟怎麼走、有什麼眉角。
Skill 就是這份文件的打包:系統 prompt + 工具定義 + 使用情境。
一個 Skill 的檔案結構長這樣:
my-skill/
├── SKILL.md # 核心:技能定義 + 使用說明
├── scripts/ # 選配:可執行腳本
├── references/ # 選配:參考文件
└── assets/ # 選配:模板、素材
重點是那個 SKILL.md,它有兩段:
---
# Frontmatter — AI 用這段判斷「什麼時候啟動這個技能」
name: code-review
description: "Review code changes for quality and security.
Use when asked to review a PR or code snippet."
---
# Code Review Skill
## 流程
1. 讀取 diff 或指定檔案
2. 檢查安全性、效能、可讀性
3. 給出具體建議,附上修改範例為什麼不把所有東西都塞進 prompt?
因為 context window 是有限的公共資源。這裡有個設計原則叫 Progressive Disclosure(漸進式揭露):
- Metadata(name + description)——永遠在 context 裡,約 100 words
- SKILL.md body——技能被觸發才載入,建議 < 5k words
- Bundled resources——AI 需要時才去讀
你不會每天出門都把整個衣櫃背在身上吧?雖然我老婆出門行李箱的容量暗示她是這樣想的。
什麼時候該寫 Skill
- 重複性任務:每次 code review 都檢查同一套清單
- 固定流程:commit message 格式、文件產出模板
- 領域知識:公司的 coding standard、特定 API 的用法
門檻很低:你只需要會寫 Markdown、會寫清楚的指令、然後你自己得先會那件事。你不能教 AI 做你自己都不會的事,雖然我試過。
MCP:AI 的萬能接頭
USB 的比喻
還記得 USB 出現之前嗎?印表機是並列埠、滑鼠是 PS/2、手機充電頭每家都不一樣。USB 統一了這些接頭。
MCP(Model Context Protocol)做的是同一件事——統一 AI 存取外部工具的方式。
沒有 MCP 的時候,你要讓 AI 讀 Notion,得自己寫 API wrapper、定義 function calling schema、處理認證和分頁。每接一個新服務就重來一次。有了 MCP:
AI Agent <-> MCP Client <-> MCP Server (Notion) <-> Notion API
<-> MCP Server (Gmail) <-> Gmail API
<-> MCP Server (GitHub) <-> GitHub API
每個 MCP Server 都講同一個協定(JSON-RPC),AI 只要會「講 MCP」就全部通吃。
實際怎麼用
以 mcporter 這個 CLI 為例:
# 安裝
npm install -g mcporter
# 設定 Notion(會跳出瀏覽器做 OAuth 認證)
mcporter auth notion
# 看有哪些工具可以用
mcporter list notion --schema
# 搜尋 Notion 裡的頁面
mcporter call notion.search query="weekly standup"
# 查詢特定資料庫
mcporter call notion.query_database database_id="abc123" \
--args '{"filter":{"property":"Status","select":{"equals":"In Progress"}}}'設定完之後,任何支援 MCP 的 AI agent 都能透過這些 Server 存取 Notion。
踩坑提醒:Notion API 回傳的 JSON 超級冗長。我有一次讓 AI 直接處理原始回傳,8 次 mcporter 呼叫就灌了 2.4MB 進 session,直接 context_length_exceeded 爆掉。解法是讓 AI 只提取 title + id,馬上寫入檔案,不要在記憶體裡累積。
需要的知識
老實說比 Skills 多不少:
- API 基礎:REST、HTTP method、status code
- OAuth 流程:大多數 MCP Server 都用 OAuth 認證
- JSON Schema:工具的輸入輸出定義
- JSON-RPC 概念知道就好,不用自己實作
那我到底該用哪個?
| 你想做什麼 | 用什麼 | 複雜度 |
|---|---|---|
| 自動 Code Review | Skill | ★★ |
| 固定格式的文件產出 | Skill | ★★ |
| 讓 AI 讀寫 Notion | MCP | ★★ |
| 讓 AI 收發 Gmail | MCP | ★★ |
| 多系統串接(Notion→GitHub→Slack) | MCP + Skill | ★★★ |
| 24/7 自動化助理 | Bot(見下一篇) | ★★★★ |
建議路線:先從 Skills 開始。門檻最低,一個 SKILL.md 就能跑。等你需要串接外部系統了再搞 MCP。等你需要 24/7 運行了再建 Bot。
學習時間粗估:
| 路線 | 前置知識 | 投入時間 |
|---|---|---|
| Skills | Prompt Engineering + Markdown | 1-2 天 |
| MCP | + API 基礎 + OAuth | 3-5 天 |
| Bot | + Token 管理 + Session 設計 + DevOps | 1-2 週 |
延伸閱讀
- [[ai/07-2-building-ai-bot|[ai/07-2] 自建 AI Bot 實戰]] — 從 Gateway 到 Session 管理的完整配置
- Prompt Engineering — 所有路線的共同基礎
- AI 輔助開發工具 — 從 Copilot 到 Agent 的演進
Skills 教 AI 怎麼做事,MCP 教 AI 怎麼跟外面溝通——剩下的就是你教 AI 別亂花你的 token。