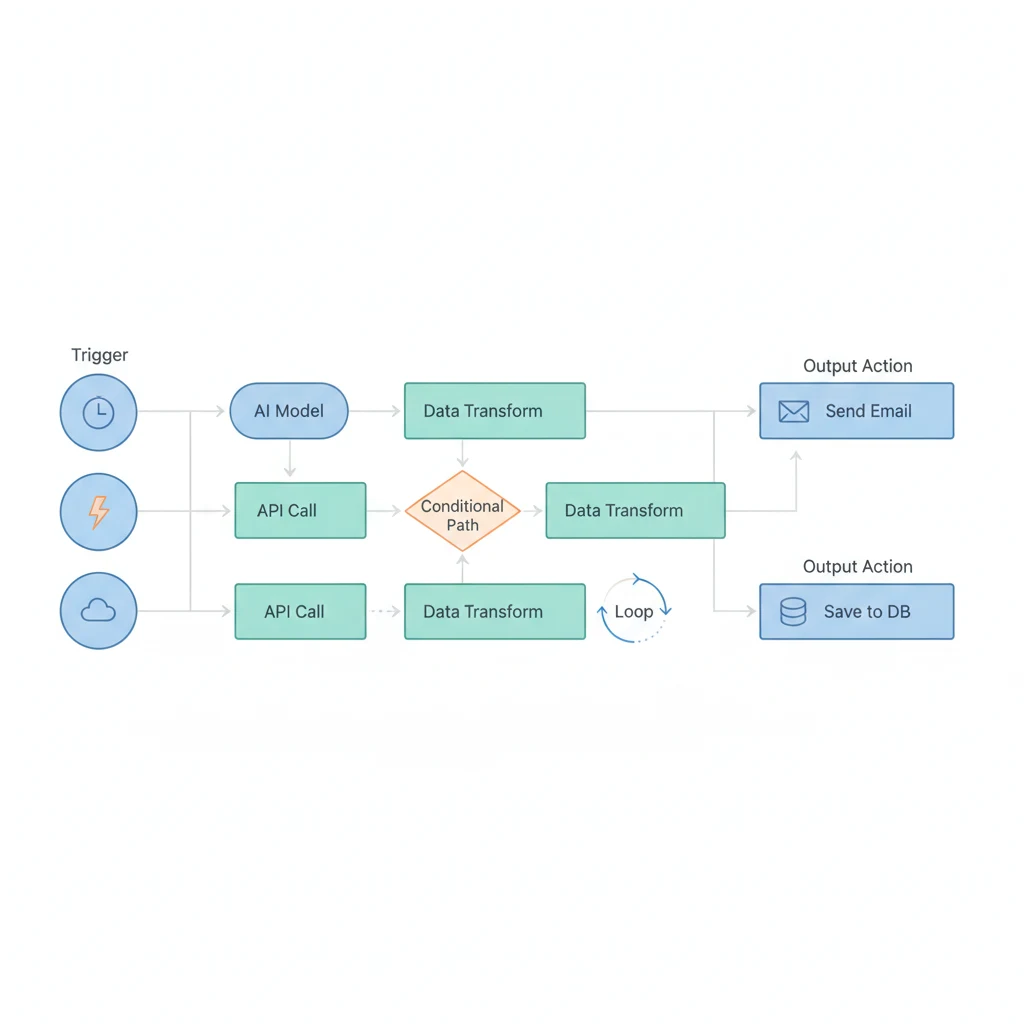
你有沒有發現,大部分「AI 應用」的介紹都在講一問一答?但你真正想做的是:收到信 → 分類 → 查資料 → 回覆 → 存記錄 → 通知人。這種多步驟的流程,才是 AI 真正值錢的地方。
先講結論
AI 工作流自動化有三個層級:
| 層級 | 工具 | 適合誰 | 用在哪 |
|---|---|---|---|
| No-Code | n8n / Zapier | PM、行銷、營運 | 固定流程自動化 |
| Low-Code | LangChain | 開發者 | RAG、複雜 AI chain |
| Agent | CrewAI / Claude Code | AI 工程師 | 需要 AI 自己做決策 |
核心原則:能用簡單工具解決的,就不要用複雜的。
如果你能畫出流程圖 → 用 n8n。 如果你畫不出來(因為每次路徑不同)→ 才考慮 Agent。
為什麼單次 LLM 呼叫不夠
一次 LLM 呼叫 = 一個問題、一個回答。但真實世界長這樣:
收到客戶訊息 → 判斷意圖 → 查 FAQ → 查不到就轉人工
→ 如果是投訴 → 建 ticket → 通知主管
單次 LLM 做不到多步驟、做不到呼叫 API、做不到條件分支、做不到排程。你需要的是一個「編排系統」來串接這些步驟。
你當然可以寫 Python script 把步驟串起來。但當你有 10 個以上的自動化流程、需要非工程師也能改、需要監控和錯誤通知的時候——手動管理就是噩夢。
n8n:大部分場景的首選
n8n 是開源的工作流自動化平台,拖拽式建流程、400+ 整合、可以自己架。
為什麼我推薦 n8n 而不是 Zapier?
- 開源、可自架:資料不離開你的伺服器
- 免費額度無限(自架版)
- 內建 AI 節點:直接接 OpenAI / Claude,不用寫 code
- 有程式碼節點:n8n 搞不定的,用 JS/Python 補
適合的場景:
- Email 分類自動回覆
- RSS 抓新聞 → AI 摘要 → 丟 Slack
- 每日報表(查 DB → AI 分析 → 寄信)
- PR 開啟 → AI 摘要 diff → 貼 comment
- 翻譯管線(中文稿 → AI 翻英文/日文 → 人工校稿)
一句話:流程固定、步驟明確的事,n8n 全包。
LangChain:當你需要 RAG 或複雜 chain
LangChain 是 Python/JS 的 LLM 應用框架,核心理念是把 LLM 操作拆成可組合的元件。
什麼時候需要 LangChain?
- 你要做 RAG(語意搜尋 + LLM 回答)
- 你的 AI 流程需要串接 3 個以上步驟
- 你需要 Memory(記住對話歷史)
- 你需要動態選擇工具
什麼時候不需要?
如果你只是要呼叫一次 LLM 做翻譯或摘要:
# 直接用 OpenAI SDK,不需要 LangChain
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": "翻譯成中文:Hello"}]
)LangChain 是為「編排」而生的,不是為「簡單呼叫」而生的。用 LangChain 做翻譯就像用大砲打蚊子。蚊子是死了沒錯,但你的專案多了 50 個 dependency。
Agent:最後的手段
AI Agent = LLM + 工具 + 記憶 + 規劃能力。它能自己決定「接下來要做什麼」。
User: 比較台北和東京今天的天氣
Agent 思考: 先查台北天氣
Agent 行動: call get_weather("台北") → 32°C 晴天
Agent 思考: 再查東京
Agent 行動: call get_weather("東京") → 28°C 多雲
Agent 思考: 可以比較了
Agent 回答: 台北 32°C 晴天,東京 28°C 多雲,台北高 4 度。
聽起來很酷對吧?但 Agent 有四個大問題:
- 成本爆炸:一個複雜任務可能 10-50 次 API call。Workflow 每次 0.05-0.10
- 不可預測:相同輸入可能走不同路徑
- 會幻覺工具:「發明」不存在的工具、用錯參數
- Debug 困難:Workflow 看流程圖就行,Agent 是黑盒子
我的建議:80% 用 Workflow,20% 用 Agent。 Agent 適合研究報告撰寫、程式碼審查、探索性任務這種「每次路徑可能不同」的情境。
真實場景快速對照
| 你想做的事 | 用什麼 | 為什麼 |
|---|---|---|
| Email 自動回覆 | n8n | 流程固定 |
| 客服意圖分類 | n8n + AI node | AI 做分類,流程固定 |
| 文件問答系統 | LangChain RAG | 需要語意搜尋 |
| 每日報表 | n8n | 排程 + DB 查詢 + AI 摘要 |
| 程式碼審查 | Agent | 需要理解、分析、建議 |
| 資料同步 | n8n(不用 AI) | 根本不需要 AI |
| 研究報告 | Agent | 需要搜尋、閱讀、綜合 |
| PR 摘要 | n8n + AI node | 拿 diff → 分析 → 貼回去 |
混合使用才是正解
實務上最有效的做法:n8n 做流程編排,需要複雜 AI 的步驟呼叫 LangChain API:
外部觸發 → n8n(流程編排)
│
┌──────────┼──────────┐
▼ ▼ ▼
AI 節點 LangChain Agent
(分類/摘要) API (RAG) API (複雜推理)
把 LangChain 包成 FastAPI:
from fastapi import FastAPI
app = FastAPI()
@app.post("/api/rag/query")
async def query_rag(request: dict):
answer = rag_chain.invoke(request["question"])
return {"answer": answer}n8n 用 HTTP Request 節點呼叫就好。各司其職,乾淨俐落。
下一篇
想看 n8n 和 LangChain 的完整實作?Docker 部署、AI 節點設定、RAG chain、Agent 範例都在這:
能用 if-else 解決的問題就不要用 AI。能用 n8n 解決的就不要用 LangChain。能用 LangChain 解決的就不要用 Agent。越簡單越可靠。