ChatGPT 是一問一答的翻譯機。Claude Code 是會自己去找檔案、改 code、跑測試的實習生。差別不在模型,在 Agent 架構。
先講結論
Agent = LLM + 工具 + 記憶 + 迴圈。
普通的 LLM 呼叫是「輸入 → 輸出」,一次就結束。Agent 是一個迴圈:行動 → 觀察結果 → 決定下一步 → 再行動,直到任務完成。
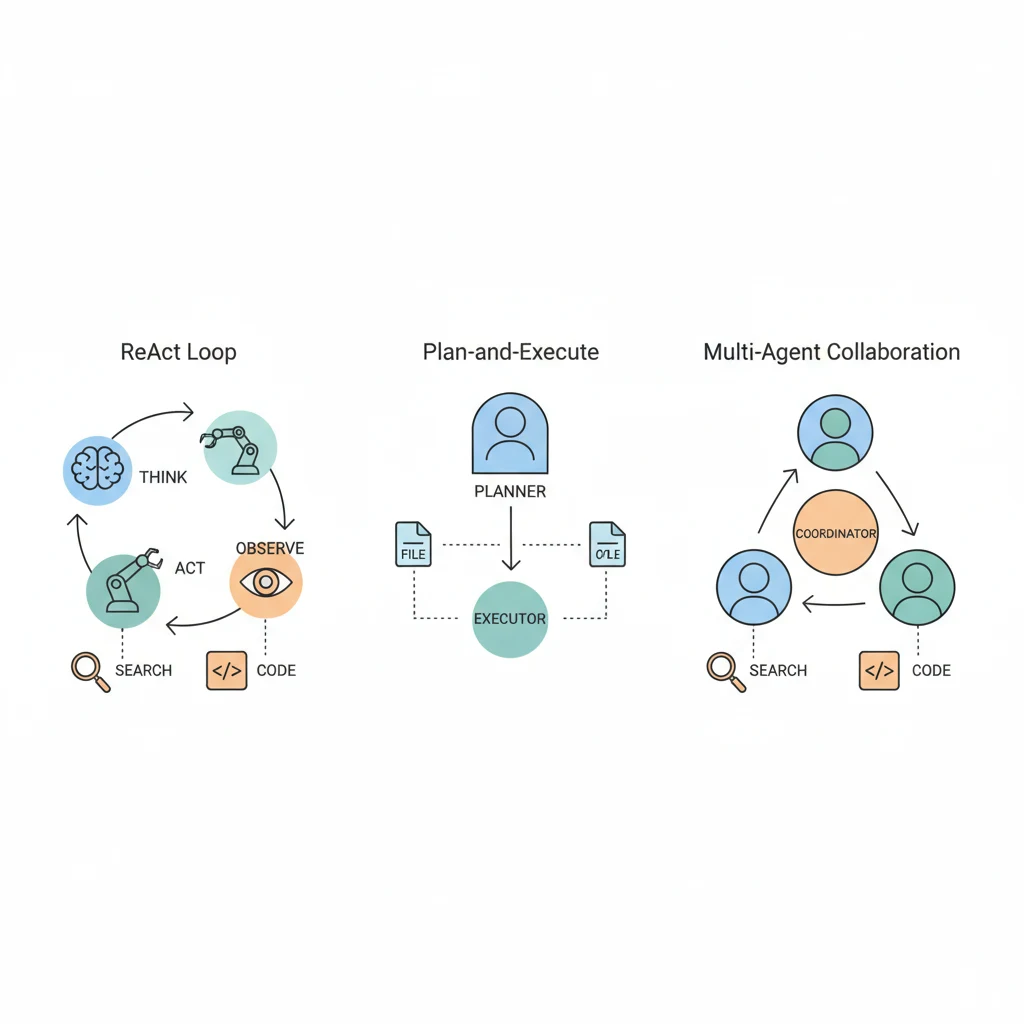
三個你最常遇到的 Agent 模式:
- ReAct:想一步做一步(適合簡單任務)
- Plan-and-Execute:先規劃再執行(適合複雜任務)
- Multi-Agent:多個 Agent 分工合作(適合超大任務)
90% 的場景用 ReAct 就夠了。 不要一上來就用 Multi-Agent,就像你不會為了煮泡麵請三個廚師。
ReAct:最基礎也最實用的模式
ReAct(Reasoning + Acting)就是讓 LLM 交替「想」和「做」:
User: 比較台北和東京今天的天氣
Think: 我需要查台北的天氣
Act: call weather_api("台北") → 25°C 晴天
Think: 再查東京
Act: call weather_api("東京") → 18°C 多雲
Think: 兩個都查到了,可以比較
Answer: 台北 25°C 晴天,東京 18°C 多雲,台北高 7 度。
每做一步就觀察結果,再決定下一步。這個模式的好處是推理過程透明,你可以看到它每一步在想什麼,不是黑盒子。
缺點? 長任務容易「迷路」。想像一下你給它一個需要 15 步才能完成的任務——到第 10 步的時候,context window 已經塞滿了前面的思考過程,品質開始下降。
我在做 ClawdBot heartbeat 的時候就遇過這個問題。Agent 的 session 累積到 166K tokens 之後,它就開始偷懶——每次 heartbeat 都只回一個 HEARTBEAT_OK 然後什麼都不做。就像實習生上班上到第三個月開始摸魚。
Plan-and-Execute:先想清楚再動手
當任務太複雜、ReAct 會迷路的時候,就需要 Plan-and-Execute:
任務: 重構整個認證系統
Plan(規劃階段):
1. 分析現有認證流程
2. 設計新的 JWT + Refresh Token 架構
3. 修改 middleware
4. 更新所有 API endpoint
5. 寫測試
Execute(執行階段):
→ 逐步執行,每步完成後回報
→ 遇到問題可以 Re-plan
關鍵在於分離「想」和「做」。 Planner 只負責全局視野,Executor 只負責執行單步。這樣每個 Agent 的 context 都很乾淨。
Claude Code 的 Plan Mode(/plan)就是這個模式的實作——Plan Mode 裡只能讀和搜尋,不能改 code。等你看過計劃覺得 OK,才開始執行。
我覺得這是最聰明的設計之一。有多少次你看到 AI 還沒搞清楚全貌就開始瘋狂改 code?然後把整個專案改得面目全非。
Multi-Agent:當一個人不夠用
當任務需要不同「角色」的能力時,就把它拆給多個 Agent。
主從模式(最常用)
使用者 → Team Lead(分配任務)
├→ Researcher(搜尋分析)
├→ Coder(寫 code)
└→ Tester(測試驗證)
← Team Lead(整合結果)
我自己的 OpenClaw 系統就是這種架構:4 個 Agent(main、ops、content、watchdog),各有各的 workspace、Discord 頻道、heartbeat 排程。ops 負責監控,content 負責產出內容,watchdog 負責確認大家還活著。
好處:每個 Agent 的 context 互不干擾。壞處:Agent 之間的溝通是有成本的——每次 SendMessage 都消耗 token。
其他模式(知道就好)
- Pipeline:A 做完傳給 B,B 做完傳給 C。適合固定流程(像內容生成管線)
- Debate:一個 Agent 提方案,另一個 Agent 挑毛病。適合需要批判性思考的場景(code review、風險評估)
工具設計:Agent 的能力上限
Agent 再聰明,沒有工具就只能嘴砲。工具設計決定了 Agent 的能力邊界。
好的工具設計:
| 原則 | 好的 | 不好的 |
|---|---|---|
| 單一職責 | read_file(path) | do_everything(action, params) |
| 清晰命名 | search_database | tool_1 |
| 錯誤訊息有用 | "File not found: /path/to/file" | "Error occurred" |
Function Calling vs MCP: Function Calling 是你在 prompt 裡自己定義工具。MCP 是標準化協定,可以同時接多個 MCP Server(Notion、Gmail、GitHub),Agent 自動知道有哪些工具可用。MCP 更靈活,但要學的東西也更多。
下一篇
Agent 的記憶管理和錯誤處理是另一個大坑——context 爆滿怎麼辦?Agent 開始無限迴圈怎麼辦?
Agent 就像實習生——能力不差,但你不能扔一句「把這個搞定」就走開。你得告訴他怎麼做、給他工具、然後盯著他。