工程師不需要會訓練模型,但你得聽懂會議上大家在講什麼。這篇幫你用 10 分鐘搞定。
先講結論
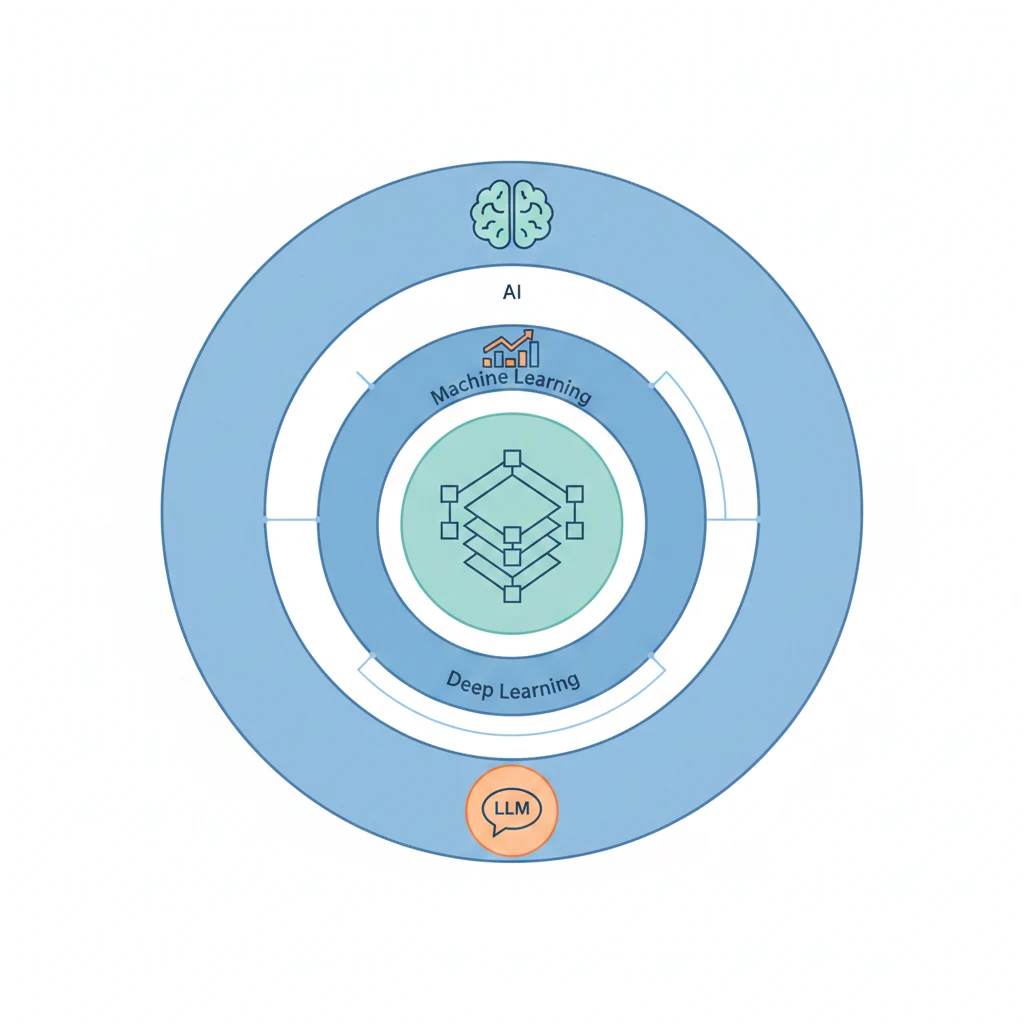
AI、ML、DL、LLM 這四個詞的關係就像俄羅斯套娃:
AI(人工智慧)
└── ML(機器學習)
└── DL(深度學習)
└── LLM(大型語言模型)
你現在每天在用的 ChatGPT、Claude、Gemini,都是最裡面那層——LLM。但你不需要從外面那層慢慢學進來,直接從 LLM 開始用就對了。
這篇文章教你的不是怎麼訓練模型(那是 ML Engineer 的工作),而是讓你在技術會議上聽到「我們用 RAG 接上 7B 的 model 做 fine-tune」的時候,不會只能點頭微笑。
AI:比你想的更廣,也更無聊
你有沒有想過,為什麼垃圾郵件過濾器也算 AI?
因為 AI 的定義其實超廣——任何「讓機器表現出智慧行為」的技術都算。這包括 90 年代那種用一堆 if-else 寫出來的醫療診斷系統(叫做 Expert System),也包括現在會寫程式碼的 Claude。
重點來了:AI ≠ Machine Learning。ML 只是實現 AI 的其中一種方法,只是剛好目前最成功的方法。
所以下次有人說「我們要導入 AI」,你可以先問一句:「你說的 AI 是指 rule-based 的自動化,還是要用到 ML?」——光這一句就能看出對方懂不懂。
ML:讓機器自己找規律
傳統寫程式的思路是:你告訴電腦規則,它照著做。
傳統:Rules + Data → Answer
ML: Data + Answers → Rules (Model)
舉個例子:你要做垃圾郵件過濾器。
- 傳統做法:手動寫規則——包含「免費」「中獎」就標記垃圾信。但詐騙集團也會進化啊,你永遠寫不完。
- ML 做法:丟 10 萬封已經標記好的信件給機器,讓它自己學出「什麼長相的信是垃圾」。
ML 有三種學法,你知道名字就好:
- Supervised Learning(監督式):有標準答案。「這封信是垃圾信嗎?是/不是」
- Unsupervised Learning(非監督式):沒有答案。「幫我把這些客戶自動分群」
- Reinforcement Learning(強化學習):靠獎懲學習。AlphaGo 就是這樣學會下圍棋的
我一開始也覺得這三個名字取得很讓人想睡覺。
DL:就是很多層的神經網路
Deep Learning 是 ML 的一個子集。「Deep」指的是神經網路很多層(layer)——傳統 ML 可能 1-2 層,DL 動輒幾十到幾百層。
你不需要知道數學細節,但你要知道三個架構名稱,因為別人會一直提到:
| 架構 | 擅長什麼 | 代表 |
|---|---|---|
| CNN | 看圖片 | 人臉辨識、YOLO 物件偵測 |
| RNN/LSTM | 處理序列(已過時) | 以前的翻譯系統 |
| Transformer | 處理文字(現在的主流) | GPT、Claude、BERT 全都是 |
2017 年 Google 發表了一篇論文叫 “Attention Is All You Need”(這名字夠狂吧),提出了 Transformer 架構。從此以後,基本上所有你聽過的 AI 模型都是 Transformer 的後代。
LLM:你每天都在用的東西
LLM(Large Language Model)就是基於 Transformer 架構、用海量文字資料訓練出來的超大模型。
它的本質其實很簡單:一個超級強大的文字接龍機器。你給它一段文字,它預測接下來最可能出現什麼字。就這樣。只是這個「預測」做得好到嚇人。
LLM 又分成幾個流派:
| 類型 | 代表 | 擅長 |
|---|---|---|
| Decoder-only | GPT、Claude、LLaMA | 生成文字(對話、寫作) |
| Encoder-only | BERT | 理解文字(分類、搜尋) |
| Multimodal | GPT-4o、Gemini | 圖文都能處理 |
你現在最常接觸的 ChatGPT 和 Claude 都是 Decoder-only 類型——專門負責「生」東西出來。
所以工程師到底要學到哪裡?
老實說,我覺得大部分工程師不需要理解 backpropagation 的數學公式,也不需要會寫 PyTorch。你需要的是:
- 會用 API 呼叫模型(這跟呼叫任何第三方 API 一樣簡單)
- 聽得懂 AI 術語(下一篇會講最常見的那些)
- 能判斷一個 AI 方案靠不靠譜(這才是真本事)
把 LLM 想成一個很聰明但不太可靠的初級工程師——它的產出永遠需要你 review。如果你能記住這一句話,你就已經比很多盲目信任 AI 的人更懂了。
這個系列還會聊什麼
這是「AI 從零開始」系列的第一篇。接下來:
- 下一篇:Token、Embedding、Temperature——LLM 最常遇到的術語
- Fine-tuning vs RAG vs Prompt Engineering:三條路怎麼選
- AI 部署與成本:API 還是自己架?
- AI 的風險清單:上線前你必須知道的事
如果你已經知道 AI/ML/DL/LLM 的區別,直接跳到下一篇看術語吧。不丟人。