每個人都覺得災難不會發生在自己身上,直到它發生。然後你才發現:備份檔案損壞了、備份的 DB 版本不對、或者根本沒有人試過 restore。
先講結論
備份如果不能還原,就不算備份。定義 RPO(最多能丟多少資料)和 RTO(最多能停多久),然後定期演練 restore。3-2-1 規則(3 份資料、2 種媒介、1 份異地)是最低標準。所有備份都要加密、所有還原都要驗證、所有演練都要記錄。
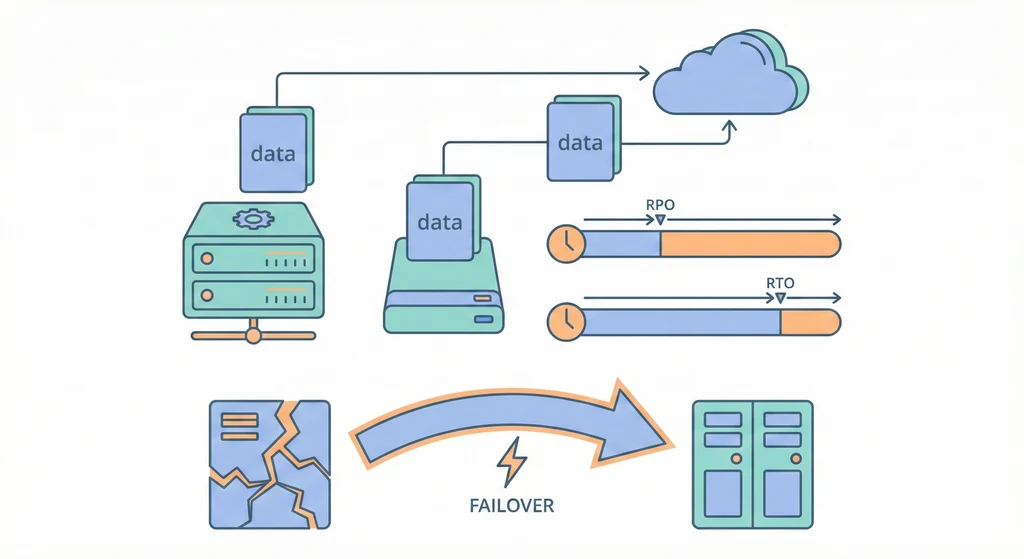
RPO 和 RTO:先搞清楚你能承受什麼
在開始談工具之前,先問兩個問題:
RPO(Recovery Point Objective)——如果現在系統掛了,你能接受丟掉最近多久的資料?一小時?一天?完全不能丟?
RTO(Recovery Time Objective)——系統掛了之後,你能接受多久才復原?一小時?四小時?一天?
這兩個數字決定了你要用什麼備份策略。RPO 趨近零需要即時複寫,成本很高。RTO 趨近零需要 active-active 架構,更貴。
大部分團隊從來沒有明確定義過這兩個數字,然後在災難發生的時候才開始爭論「到底要先救什麼」。
3-2-1 規則:最少做到這樣
- 3 份資料:一份原始、一份本地備份、一份異地備份
- 2 種媒介:不要全部放在同一個雲端服務商
- 1 份離線或異地:就算整個 region 掛了也能恢復
聽起來很基本對吧?但我看過太多團隊的「備份」就是同一台機器上的另一個資料夾。機器硬碟壞了,備份跟原始資料一起升天。
Snapshot 不等於備份
很多人以為「我有開 snapshot 就是有備份了」。不是的。
Snapshot 是同一平台內的時間點快照,它通常:
- 不能跨區域還原
- 依賴原始平台(平台掛了 snapshot 也不見了)
- 不一定能獨立驗證
真正的備份是一份 可搬移、可獨立驗證的副本。
# PostgreSQL 備份
pg_dump -Fc -f backup.dump mydb
# 驗證:還原到 staging 確認資料正確
pg_restore -d mydb_staging backup.dump勒索病毒:備份也要防
近幾年勒索病毒攻擊的套路越來越狠——不只加密你的線上資料,連備份一起加密。如果你的備份跟正式環境用同一組權限,那備份也會中招。
防禦方式:
- Immutable backup(WORM)——寫入後一段時間內不能修改或刪除
- 用獨立帳號管理備份,跟正式環境完全隔離
- 開啟 Object Lock 設定保留期限
最重要的事:演練
備份做了、排程跑了、S3 上有檔案了——然後呢?你試過 restore 嗎?
我見過的災難場景:
- 備份檔案格式跟當前 DB 版本不相容
- 備份有加密但解密金鑰存在同一台被攻擊的機器上
- Restore 過程需要兩小時,但 RTO 承諾一小時
- 上次演練是八個月前,流程已經完全過時
沒有演練過的 DR 計畫就是一份小說。 至少每季做一次完整的還原測試,測 RPO 和 RTO 是否符合預期,測完更新 runbook。
延伸閱讀
備份最悲傷的故事不是「沒有備份」,而是「有備份但 restore 不了」。差別在於:前者你知道自己沒準備,後者你以為自己準備好了。