系統一定會壞,問題是你準備好了沒
一句話總結:生產環境出問題不是意外,是必然。差別在於你是手忙腳亂還是按 SOP 冷靜處理。
結論先講:成熟的工程團隊不是不出事故,是出了事故之後能在 30 分鐘內恢復,然後從每次事故裡讓系統變得更強。
不管你的 code 多嚴謹、測試覆蓋率多高、基礎設施多冗餘——硬碟會壞、網路會斷、第三方服務會掛、人會手滑。這些事情一定會發生。
差別在於你是怎麼面對的:
- 你是使用者打電話來才知道出事了,還是監控系統在影響擴大前就告警了?
- 你是在 Google 上瘋狂搜尋解法,還是打開 Runbook 按步驟執行?
- 你是找到那個「犯錯的人」然後罵一頓了事,還是做 Post-mortem 找出系統性問題?
這就是事故管理的意義。不是消除所有故障(不可能),是建立一套流程讓你在面對故障的時候不慌。
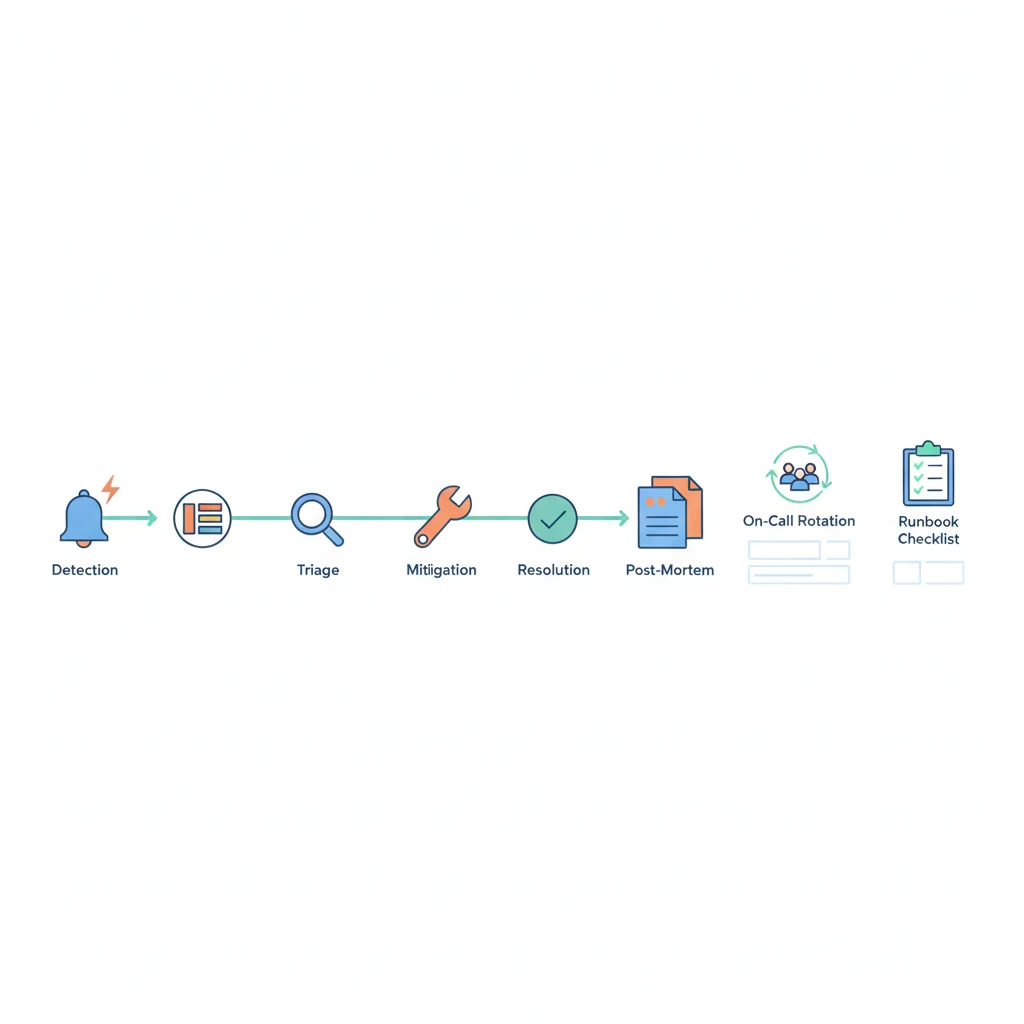
事故生命週期:六個階段的閉環
每一次事故都走過這六步:
偵測 → 分級 → 應變 → 解決 → 覆盤 → 預防 → (回到偵測)
最後一步「預防」的輸出會回饋到第一步「偵測」——告警規則更新了、監控更完善了、Runbook 更新了。這樣系統的可靠性才會隨著時間一直上升,而不是同樣的事故反覆發生。
嚴重等級:不是所有事故都要全員集合
你不需要為了一個 UI 小瑕疵在凌晨三點把 CTO 叫起來。明確的嚴重等級讓團隊知道什麼時候該緊張、什麼時候可以明天再處理。
P1 (Critical):核心服務全掛,大量用戶受影響。主資料庫掛了、全站打不開、支付系統全面失敗。15 分鐘內回應,每 15 分鐘更新一次。
P2 (Major):核心功能嚴重降級。API 回應超過 10 秒、部分地區登入不了。30 分鐘內回應。
P3 (Minor):非核心功能異常。推播通知延遲、報表匯出失敗。4 小時內回應。
P4 (Low):不影響服務的小問題。下個工作日處理。
判定等級看四個面向:影響多少用戶、有沒有影響營收、有沒有資料風險、問題會不會隨時間惡化。
On-call:不是懲罰,是專業
On-call 是事故管理的第一道防線。設計不好的 On-call 制度會讓工程師心生怨恨,設計好的則是團隊成熟度的指標。
幾個原則:
- 一週一輪:避免單次值班太長造成疲勞
- 至少兩層:Primary 沒回應自動升級到 Secondary
- 公平補休:週末值班要有對等的補休,不然沒人想排
- 新人保護期:新進工程師先 shadow 資深工程師 2-4 週才上陣
- Follow-the-sun:跨時區團隊利用時差,讓每個人只負責自己的工作時段
升級路徑要事先定好:
告警觸發 → On-call Primary(5 分鐘無回應)
→ On-call Secondary(10 分鐘無回應)
→ Team Lead(15 分鐘無回應)
→ VP / CTO
事故指揮官:不是修東西的人
P1 和 P2 事故需要一個事故指揮官(Incident Commander, IC)。IC 的工作不是親自動手修——他是統籌全局的人。
IC 做什麼?
- 宣告事故等級,啟動對應流程
- 組建應對團隊,找到對的人來處理對的問題
- 分派任務,避免重複工作
- 每 15 分鐘向利害關係人更新進展
- 團隊對修復方案有分歧時做最終決定
- 確保所有關鍵事件被記錄(Post-mortem 要用)
- 確認服務恢復後宣告事故結束
IC 通常由資深工程師或 Tech Lead 輪流擔任。小團隊裡 On-call Primary 可以兼任。
事故溝通:透明比完美重要
事故發生時,溝通混亂是讓情況惡化的催化劑。
內部:開專屬事故頻道(#incident-2024-1015-db-outage),所有討論集中在這裡。IC 定期發結構化更新:目前狀況 → 正在做什麼 → 下一步 → 預計恢復時間。
外部:用 Status Page 讓使用者自己查,用 Email 通知企業客戶,在社群媒體發簡短更新。
關鍵是:不知道的時候就說不知道,正在查的時候就說正在查。 使用者最怕的不是出問題,是出了問題你一句話都不說。
這篇的重點回顧
事故管理是一個從偵測到預防的閉環流程。嚴重等級幫你分配資源,On-call 確保有人回應,IC 統籌全局,溝通讓一切透明。
下一篇聊 Runbook——那本讓你凌晨三點不用動腦就能處理事故的操作手冊。
系列文章:
- 你在這裡 → 事故管理(一):事故生命週期與分級
- 事故管理(二):Runbook 操作手冊
- 事故管理(三):Post-mortem 與災難復原演練
延伸閱讀:
「事故管理不是消防隊的工作,是建築設計師的工作——差別在於你是救火還是防火。」