你做的是好「專案」還是好「產品」?
一句話總結:好專案如期如預算交付,好產品讓使用者離不開。兩者經常不是同一個東西。
結論先講:工程師應該用「產品思維」做技術決策,不是用「專案思維」。你寫的每一行程式碼,不只要能在 deadline 前跑起來,還要讓六個月後的你不會想砸鍵盤。
問十個工程師「什麼是好產品」,你會得到十個不同答案。「程式碼乾淨」、「覆蓋率 90%」、「延遲低」。問十個 PM,答案又不一樣。「用戶喜歡」、「DAU 成長」、「客戶付費」。問十個使用者?更直白——「好用」、「不會當」、「快」。
這些答案都對,但都不完整。好產品不是單一維度的極致,是多個維度之間的動態平衡。
好專案 ≠ 好產品
在專案管理的世界裡,成功的定義很簡單:如期交付、預算內、範圍符合、客戶驗收通過。三角約束全滿足,專案就算「成功」了。
但產品的世界不是這樣運作的。
場景一:好專案,壞產品。 外包團隊三個月如期交付 CRM 系統,功能完全符合需求文件,預算沒超支。專案成功結案。三個月後,客服部門的人抱怨系統太慢、操作邏輯反人類、三天兩頭出錯。半年後,公司決定換系統。
專案成功了。產品失敗了。
場景二:壞專案,好產品。 新創團隊開發協作工具,原定三個月 MVP,花了八個月。改了三次架構、重寫了兩次核心模組、超支 200%。從專案管理的角度看,這是一場災難。但上線後用戶留存率 60%,口碑傳播帶來穩定增長,一年後拿到 B 輪。
專案失敗了。產品成功了。
你想要哪一種?
為什麼工程師必須分清這件事?
因為你最佳化的目標不同,你的行為就完全不同。
最佳化「專案指標」的工程師會趕工、砍功能、跳過測試、累積技術債——反正 deadline 前交出去就好。最佳化「產品品質」的工程師會在前期花時間做架構、寫測試、優化 UX——因為他知道這東西要活很久。
專案有終點(kick-off → delivery),產品沒有(launch → iterate → sunset)。一個交付時刻看起來完美的專案,可能在上線六個月後變成維護地獄。而且專案交付後就結案了,產品卻需要持續維護、迭代、改進。
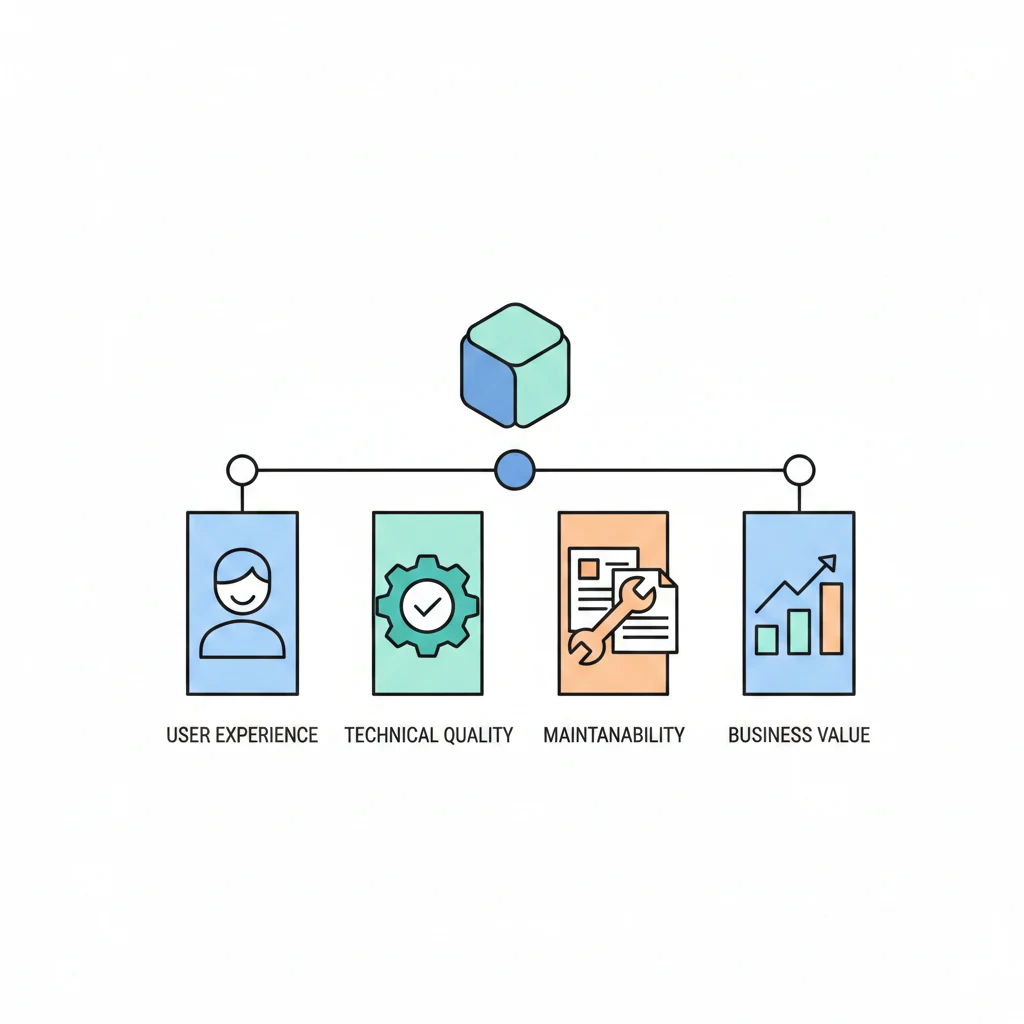
好產品的五個維度
好產品的品質可以從五個維度來衡量,這五個維度相互關聯、相互影響:
| 維度 | 核心問題 | 誰最在乎 |
|---|---|---|
| 使用者體驗 | 好不好用? | 使用者 |
| 技術品質 | 效能好不好?會不會掛? | 工程師 + 使用者 |
| 可維護性 | 半年後還改得動嗎? | 工程師 |
| 商業價值 | 有人願意付錢嗎? | PM + 老闆 |
| 團隊與流程 | 團隊能持續交付嗎? | 全部的人 |
這五個維度不是都要做到 100 分——那你大概需要 Google 的工程師人數和 NASA 的預算。重點是在你的階段和資源下,找到最適合的平衡。
使用者體驗:使用者看到的就是全部
不管你的程式碼多優雅、架構多漂亮,使用者看到的只有介面和互動。你花三個禮拜做的 Event Sourcing,使用者不知道也不在乎。他只在乎按下按鈕之後會不會有反應。
直覺性——使用者不看說明書就能上手。核心是「符合心智模型」。使用者在用你的產品之前,已經有一套基於過去經驗的操作預期。拖曳檔案到垃圾桶刪除、點欄位標題排序、Ctrl+Z 復原——這些都是已經建立的預期。好產品順應這些預期,而不是發明新操作。
工程師最常犯的錯?用技術架構來組織功能。你把設定項目按照後端 module 分類,使用者只想問:「我要改通知設定,到底在哪裡?」使用者不在乎你後端有幾個 microservice。
一致性——一個操作方式學會了,到處都能用。所有列表都用同樣的方式分頁、排序、篩選。主要操作永遠是藍色按鈕,危險操作永遠是紅色。全部用「儲存」,或全部用「提交」——不要一個頁面叫「儲存」、另一個叫「確認」、第三個叫「送出」。
回饋感——每個操作都有回應。人類對「無回應」的容忍度極低。按了按鈕什麼都沒發生,第一反應是「沒按到吧?」然後再按一次。如果那個按鈕觸發的是「購買」或「刪除」,恭喜你,使用者剛剛買了兩份或刪了兩次。
// 按鈕沒有 loading 狀態——使用者會狂點
<button onClick={handleSubmit}>提交</button>
// 有 loading 狀態——使用者知道系統在處理了
<button onClick={handleSubmit} disabled={isLoading}>
{isLoading ? '提交中...' : '提交'}
</button>容錯性——使用者犯錯時,讓他們能復原。不小心刪了重要檔案,最差的設計是直接永久刪除。好一點有確認對話框——但使用者早就養成了「無腦點確認」的習慣。再好一點有垃圾桶。最好的設計?刪除後顯示 Toast「檔案已刪除」加一個 Undo 按鈕,幾秒內一鍵復原。
Gmail 的「撤銷傳送」就是容錯設計的教科書案例。
這篇的重點回顧
好專案和好產品是兩件不同的事。工程師要用產品思維做決策,不是只看 deadline。好產品有五個維度:使用者體驗、技術品質、可維護性、商業價值、團隊與流程。使用者體驗是最外層也最容易被感知的維度——直覺性、一致性、回饋感、容錯性。
下一篇我們來看技術品質——效能、可靠性、安全性、可擴展性。
系列文章:
- 你在這裡 → 好產品的定義(一):好專案 vs 好產品 + 使用者體驗
- 好產品的定義(二):技術品質
- 好產品的定義(三):可維護性
- 好產品的定義(四):商業價值與團隊
- 好產品的定義(五):生命週期、指標與反模式
延伸閱讀:
「好產品跟好男友一樣——不是條件最好的那個,是跟你最合的那個。」