你寫的每一個
{}和new Map(),底層都是 Hash Table。
先講結論
Hash Table 用 hash function 把 key 轉成陣列 index,實現 O(1) 的查找、插入、刪除。它是你最常用的資料結構——URL routing、database indexing、session storage、DNS cache,底層全是它。代價?碰撞處理和擴容。
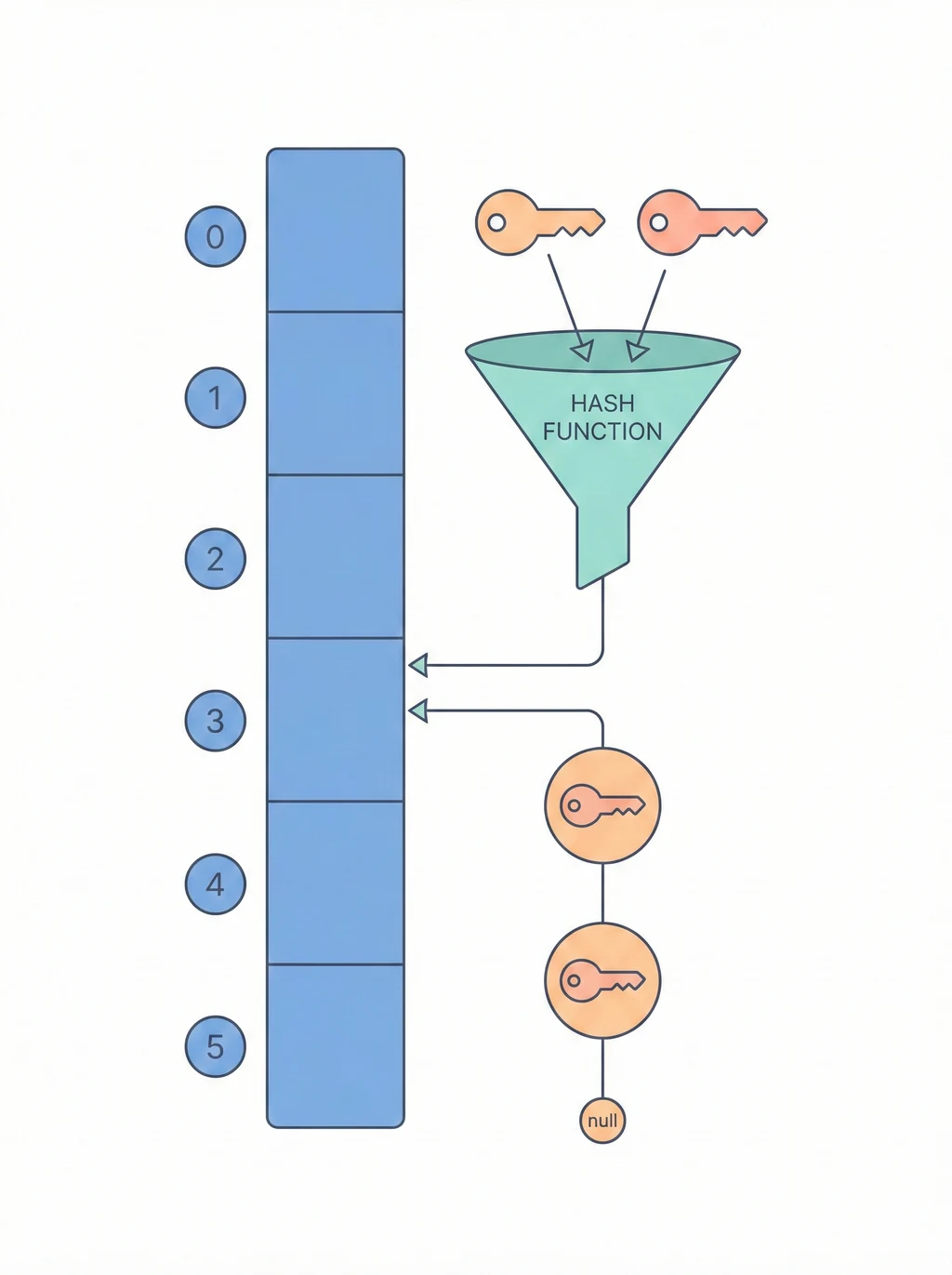
為什麼快?一個公式搞定
key "apple" → hash("apple") → 3 → buckets[3] = 100
不用遍歷,不用比較,直接算出位置。Array 查找要 O(n) 從頭找到尾,Hash Table 一步到位。
好的 hash function 三個要求:算得快、分布均勻、同 key 同結果。實務上你幾乎不會自己寫 hash function,語言都幫你做好了。
碰撞:不同 key 撞到同一格
hash("apple") % 4 = 2
hash("grape") % 4 = 2 ← 碰撞!
碰撞是必然的——鴿巢原理,key 的數量遠大於 bucket 數量。兩種主流解法:
Separate Chaining:每個 bucket 掛一條鏈表,碰撞的都串在一起。
[0]: null
[1]: "banana"=200
[2]: "apple"=100 → "grape"=400 ← 鏈起來
[3]: "cherry"=300
Open Addressing:碰撞了就往後找空位。
hash("apple") = 2 → buckets[2] = "apple"
hash("grape") = 2 → 撞了!→ buckets[3] = "grape"
Java 的 HashMap 用 Separate Chaining,而且 Java 8 之後鏈表長度超過 8 會自動轉成紅黑樹——面試常問這個。
負載因子與擴容
負載因子 = 元素數量 / bucket 數量
超過 0.75 就該擴容了(Java HashMap 的預設閾值)。擴容做什麼?開一個兩倍大的新陣列,把所有元素重新 hash 一遍放進去。這次擴容是 O(n),但 amortized 下來每次操作還是 O(1)。
JS/TS 實務:Object vs Map vs WeakMap
這三個很多人搞混:
Object {} | Map | WeakMap | |
|---|---|---|---|
| Key 類型 | string/symbol | 任意 | 只能 object |
| 順序 | 不保證 | 保證插入順序 | 不保證 |
| 大小 | Object.keys().length | .size | 無法取得 |
| GC | key 不會被回收 | key 不會被回收 | key 可被回收 |
// 設定檔、結構固定 → Object
const config = { port: 3000, host: 'localhost' };
// 動態 key-value、頻繁增刪 → Map
const sessions = new Map<string, { userId: string }>();
// 掛 metadata 但不想阻止 GC → WeakMap
const cache = new WeakMap<HTMLElement, DOMRect>();一個常見的坑:Object 的數字 key 會被自動排序。{3: 'c', 1: 'a', 2: 'b'} 遍歷出來是 1, 2, 3 而不是 3, 1, 2。如果順序重要,用 Map。
Hash Flooding 攻擊
攻擊者故意構造大量碰撞到同一個 bucket 的 key,讓 O(1) 退化成 O(n),CPU 直接 100%。
Node.js 的應對:V8 用隨機 hash seed(每次啟動不同)、body-parser 限制 JSON key 數量。你該做的:永遠不要把使用者輸入直接當 Object key。
什麼時候不該用 Hash Table?
- 資料量 < 10:Array linear search 就好,hash 的 overhead 反而更大
- 需要排序或範圍查詢:Hash Table 沒有順序概念,用 BST
- 需要前綴搜尋:用 Trie
Hash Table 是工程界的瑞士刀——什麼都能切,但偶爾也會割到自己。