LRU Cache 是面試最愛考的「設計題」,也是你每天都在受益但沒意識到的東西。
先講結論
LRU Cache = HashMap(O(1) 查找)+ 雙向鏈表(O(1) 維護使用順序)。容量滿了淘汰最久沒用的。get 和 put 都是 O(1)。瀏覽器快取、CDN、資料庫、Redis 的記憶體淘汰策略,底層都有它。
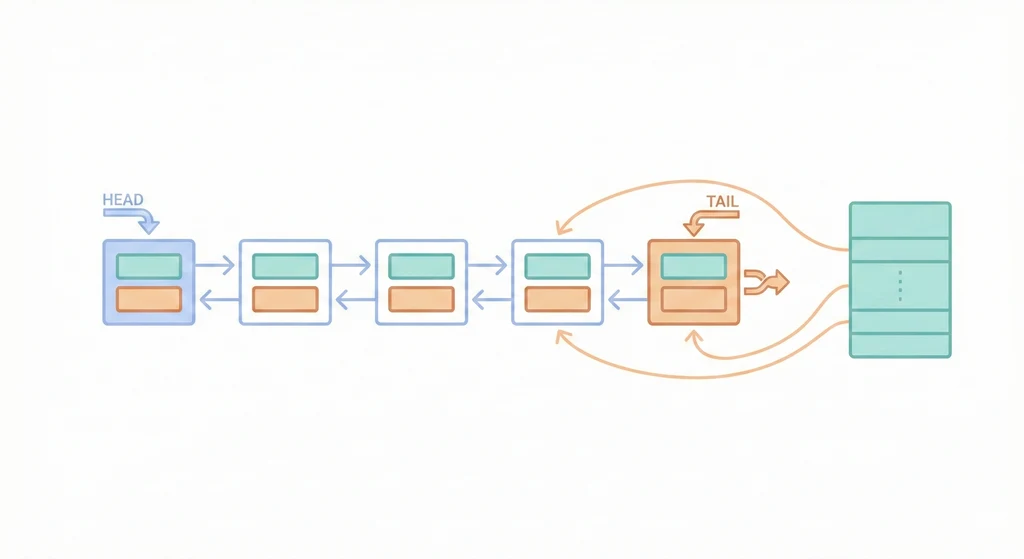
運作方式
容量: 3
put(1) → [1]
put(2) → [2, 1]
put(3) → [3, 2, 1]
get(1) → [1, 3, 2] ← 1 被用到,移到最前面
put(4) → [4, 1, 3] ← 滿了,淘汰最久沒用的 2
get(2) → -1 ← 2 已經被淘汰了
規則只有一條:每次存取都把該元素移到最前面,淘汰從最後面開始。
為什麼是 HashMap + 雙向鏈表?
先想想不用這組合會怎樣:
- 只用 Array?找元素 O(n),移動元素 O(n),全都慢
- 只用 HashMap?沒有順序概念,不知道誰最久沒用
- 只用鏈表?找元素 O(n)
- HashMap + 單向鏈表?找到元素了但刪不掉——因為要知道前一個節點才能刪,得再走一遍 O(n)
HashMap + 雙向鏈表才是正解:HashMap O(1) 找到節點,雙向鏈表 O(1) 刪除它(因為有 prev 指標),再 O(1) 插到頭部。
核心操作
int get(int key) {
if (!map.containsKey(key)) return -1;
Node node = map.get(key);
moveToHead(node); // 用到了就移到最前面
return node.value;
}
void put(int key, int value) {
if (map.containsKey(key)) {
node.value = value;
moveToHead(node);
} else {
Node newNode = new Node(key, value);
map.put(key, newNode);
addToHead(newNode);
if (map.size() > capacity) {
Node tail = removeTail(); // 淘汰最久沒用的
map.remove(tail.key);
}
}
}一個小技巧:用虛擬的 head 和 tail 節點,避免處理邊界條件。這樣不管鏈表是空的還是只有一個元素,操作邏輯都一樣。
LRU vs LFU
| LRU | LFU | |
|---|---|---|
| 全名 | Least Recently Used | Least Frequently Used |
| 淘汰依據 | 最久沒用 | 使用次數最少 |
| 偏好 | 最近用過的 | 最常用的 |
LFU 的問題:某個元素早期被大量存取但後來不再使用,它的高頻率讓它霸占快取很久。LRU 比較「健忘」,但這種健忘反而在大部分場景更實用。
Redis 的預設淘汰策略也是 LRU 的近似版(allkeys-lru)。
Java 的偷吃步
LinkedHashMap<Integer, Integer> cache =
new LinkedHashMap<>(capacity, 0.75f, true) {
@Override
protected boolean removeEldestEntry(Map.Entry eldest) {
return size() > capacity;
}
};LinkedHashMap 的第三個參數設成 true 就是 access-order 模式——存取過的元素自動移到最後面。配合 removeEldestEntry 就是完整的 LRU。面試時先手寫,然後補充「Java 其實有 built-in」,加分。
LRU Cache 的人生哲學:不管你過去多重要,只要你最近不活躍,就會被淘汰。聽起來殘酷,但你的瀏覽器每天都在這麼做。