結論先講
很多人對 Redis 的認知是「記憶體版 key-value 儲存」。這不完全對。Redis 的快速來自兩點:
- 資料在記憶體(是基礎,不是全部)
- 對每種操作選最優資料結構
一個 Redis list 在長度 < 128 時用 ziplist(省記憶體),>= 128 時切換到 linkedlist(操作 O(1))。一個 hash 在鍵值少時用 ziplist,多時切換到 hash table。根據使用情況動態切換資料結構,這才是 Redis 真正的工程智慧。
這篇拆解 Redis 幾個核心資料結構,看業界對「選對的資料結構」如何較真。
背景:Redis 的資料模型
Redis 對外提供 5 個主要類型:
String, List, Hash, Set, Sorted Set
但內部每個類型可能有多種實作,根據資料大小動態切換。
例如 Hash:
config: hash-max-ziplist-entries 128
config: hash-max-ziplist-value 64
if entries < 128 && max_value_size < 64:
use ziplist
else:
use hashtable
這是 Redis 的核心設計思想:小集合用緊湊結構,大集合用高效結構。
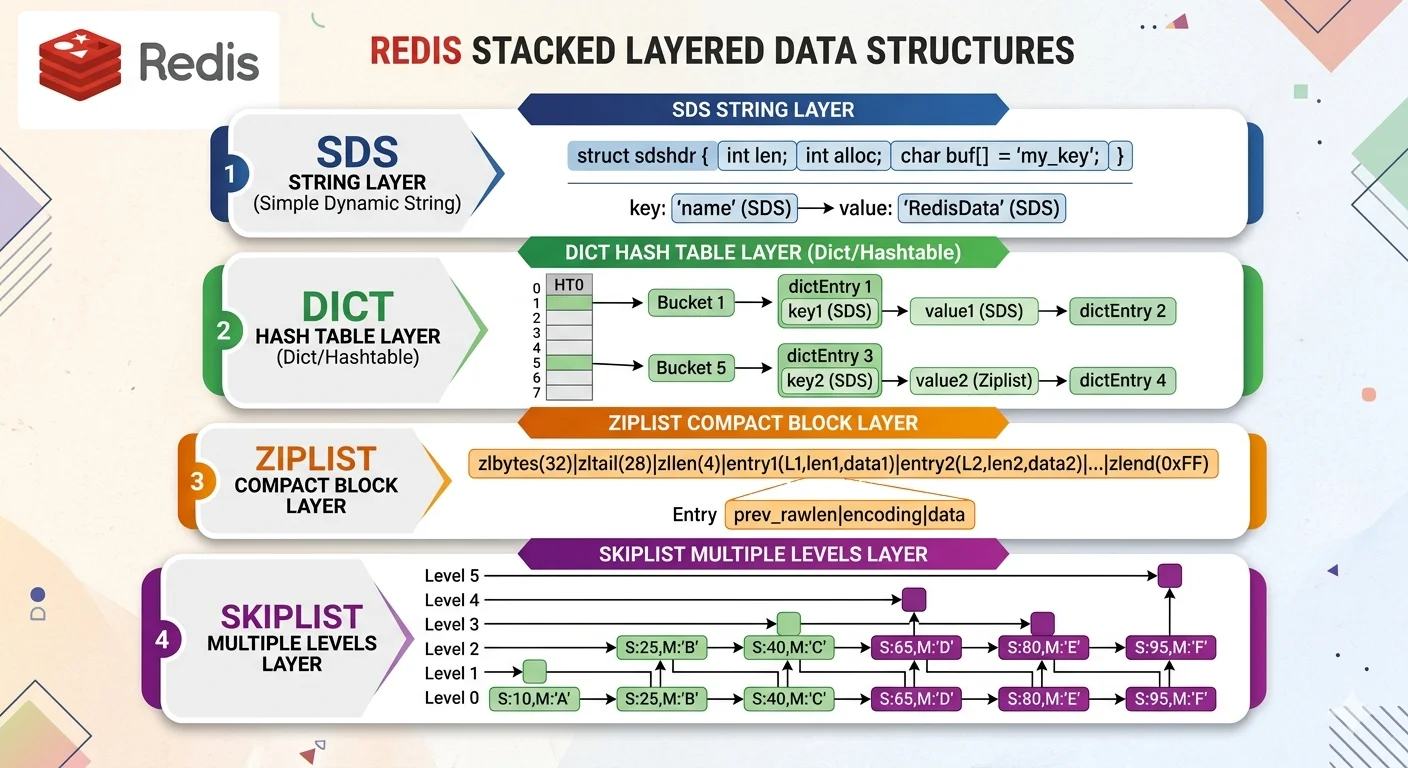
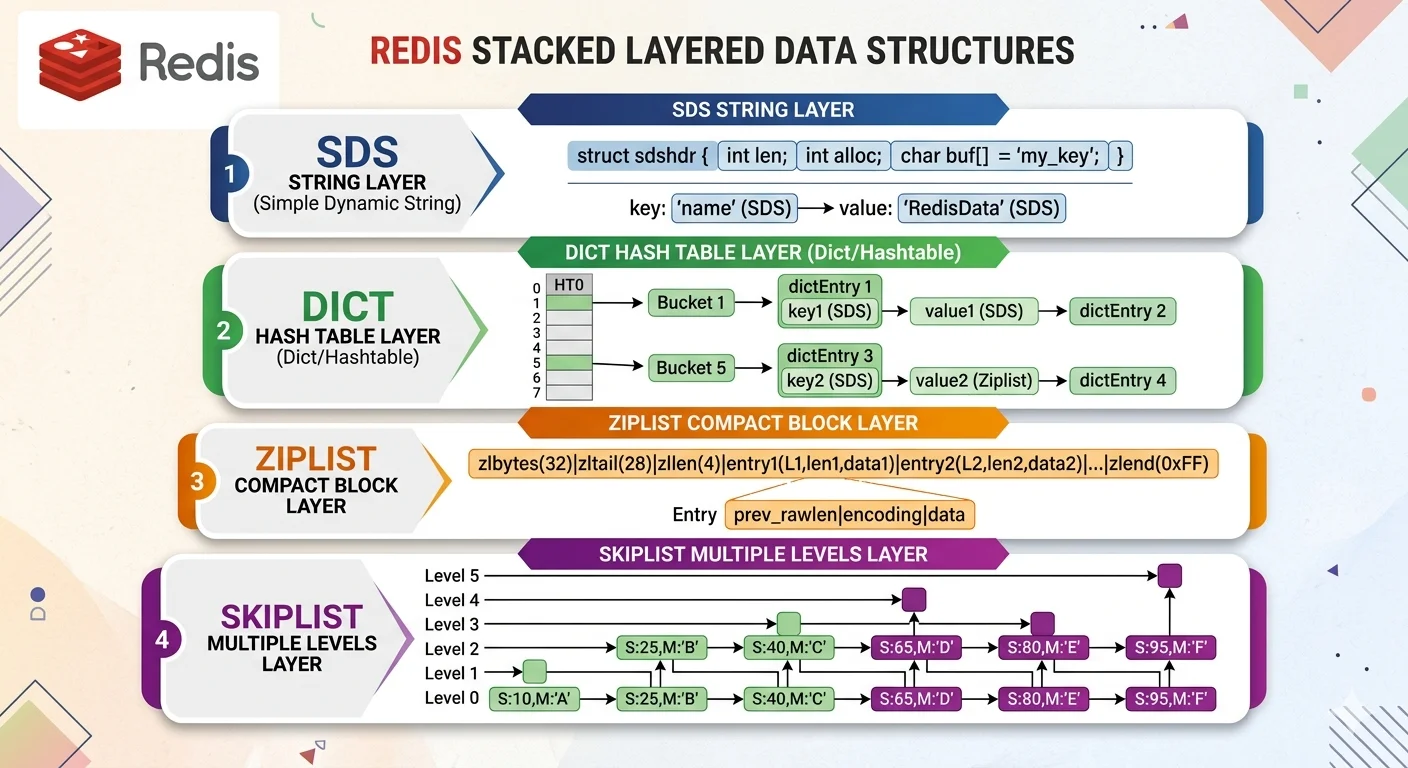
SDS(Simple Dynamic String)
Redis 的字串不是 C 原生 char*,是自己造的 SDS。
原生 C 字串的問題
char *s = "hello";
strlen(s); // O(n),要掃過找 \0
// 安全問題:忘記配置足夠空間 → buffer overflowSDS 的改進
struct sdshdr {
int len; // 字串長度
int free; // buffer 剩餘空間
char buf[]; // 實際資料(末尾加 \0 相容 C)
};好處:
strlenO(1)(直接讀len)- 安全(append 前檢查
free夠不夠) - 空間預配置(下次 append 不用重新 malloc)
- binary-safe(可以存
\0,不被當字串結尾)
空間預配置策略
append 時不只配「剛好夠」的空間,配多一點:
if new_len < 1MB:
total = new_len * 2
else:
total = new_len + 1MB
下次 append 可能就不用 malloc。用空間換時間。
Dict(Hash Table)
Redis 的 hash、set、database 的底層都是 dict。
結構
struct dict {
dictht ht[2]; // 兩個 hash table
long rehashidx; // 正在 rehash 的 index
};
struct dictht {
dictEntry **table; // hash bucket 陣列
unsigned long size; // bucket 數
unsigned long used; // 已用 entry 數
};為什麼兩個 hash table?為了漸進式 rehash。
漸進式 Rehash
傳統 hash table resize 時要一次性搬遷所有 entry。如果有 100 萬筆資料,這個操作會卡很久。
Redis 的策略:
1. 分配新的 ht[1](大 2 倍)
2. 每次操作(get / set / del)順便搬幾個 entry 從 ht[0] 到 ht[1]
3. 直到 ht[0] 清空,把 ht[1] 變成新的 ht[0]
把 rehash 的成本分散到很多次操作,每次只做一點點。
負載因子觸發
if used / size >= 1 && allow_resize:
start rehash(擴大)
if used / size < 0.1:
start rehash(縮小)
自動擴大縮小,使用者不用管。
Ziplist:小集合的緊湊儲存
ziplist 是一段連續記憶體,直接把 entries 塞在一起:
[zlbytes][zltail][zllen][entry1][entry2]...[entryN][zlend]
每個 entry 有 prev_len + encoding + content。
為什麼省記憶體
Hash table 每個 entry 要:
key指標(8 bytes)value指標(8 bytes)next指標(8 bytes)— 處理 collision- 這是一個
dictEntry的 overhead
如果 key 跟 value 都很短(例如 { "name": "John" }),overhead 比資料還大。
Ziplist 把所有 entries 塞連續記憶體,每個 entry 只佔自己需要的 byte + 幾 byte header。小集合記憶體省 5~10 倍。
代價:存取 O(n)
要找某個 entry 只能從頭掃。
何時切換
hash-max-ziplist-entries 128 # entries 超過切換
hash-max-ziplist-value 64 # 任一 value 長度超過切換
切到 hash table 前,小集合用 ziplist 省記憶體。大集合用 hash table 換效能。
Skiplist:Sorted Set 的關鍵
Sorted Set(ZSET)在小資料用 ziplist,大資料用 skiplist + hash table。
Skiplist 是什麼
一種機率性的多層連結 list:
Level 3: A -------------------> D -----> F
Level 2: A ------> B ---------> D -----> F
Level 1: A -> B -> C -> D -> E -> F
每個 node 隨機決定有幾層(用機率)。
- 搜尋:從最高層往右,遇到太大就下一層,O(log n)
- 插入:先搜尋找位置,O(log n) + 隨機層數
為什麼不用 Red-Black Tree
紅黑樹也 O(log n)。Redis 選 skiplist 的理由:
- 實作簡單(紅黑樹旋轉操作很複雜)
- 範圍查詢容易(ZRANGEBYSCORE)
- 併發友善(如果未來做 lock-free)
Sorted Set 的 hash + skiplist 雙存
ZSET 同時維護兩個結構:
hash: member -> score # 快速查 member 的 score
skiplist: 按 score 排序 # 範圍查詢
ZSCORE O(1)(查 hash)
ZRANGEBYSCORE O(log n + m)(skiplist 範圍查)
兩個結構,兩種快。
Quicklist(較新)
Redis 3.2+ 的 list 用 quicklist — linked list of ziplist:
[ziplist 1] <-> [ziplist 2] <-> [ziplist 3]
- 每個 node 是一個小 ziplist(記憶體緊湊)
- Nodes 之間 linked list(可以快速在兩端 push/pop)
- 中間插入 O(n) 但 list 很少在中間插
兼顧記憶體跟操作效能。
設計取捨:動態結構切換的代價
好處
- 小集合省記憶體(10 倍以上)
- 大集合保持效能
- 使用者完全無感
代價
- 實作複雜(每個類型要支援兩種結構)
- 邊界條件多(剛好到閾值時的切換)
- 測試困難(小/大切換路徑都要測)
Redis 的 code base 很大比例在處理這些切換邏輯。但從使用者看,這是值得的。
學到什麼
教訓 1:沒有萬用資料結構
Hash table O(1),但小集合 overhead 大。Linked list 操作兩端 O(1),中間 O(n)。看使用模式選資料結構,不是選「最快的」。
教訓 2:空間跟時間經常可互換
SDS 的空間預配置、ziplist 的 O(n) 換省空間、skiplist 用冗餘層數換 O(log n)。記憶體多換時間少,反之亦然。根據情境選。
教訓 3:漸進式搬遷是大集合操作的通解
Rehash 分攤到多次操作、GC 分攤、migration 分攤。一次性大操作會卡住,分攤可以維持穩定 latency。這個技巧在很多系統都用得到。
教訓 4:動態選結構是工程智慧
教科書通常講「用 X 結構解 Y 問題」。實戰常常是「小資料用 A,大資料用 B,中間切換」。Redis 對這個思維做到極致。
延伸閱讀
- Redis 官方 data types 文件
- Redis source code(C)
- 《Redis Design and Implementation》by Huangz — 非常細的源碼導讀
相關文章
- OSS 源碼深讀系列
- Case Studies 主索引
- Redis 使用實戰(另一個角度)
- Backend Roadmap B03 資料持久化