Bloom Filter 回答的不是「是」或「不是」,而是「一定不是」或「可能是」。這個「可能」撐起了無數大規模系統。
先講結論
Bloom Filter 用極少的空間判斷元素是否存在於集合中。它有假陽性(說存在但其實不在),但絕對沒有假陰性(說不在就一定不在)。不能刪除、不能列舉。用在快取穿透防護、垃圾郵件過濾、URL 去重等場景。
原理:多個 hash + 一個 bit array
bit array(初始全 0):
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
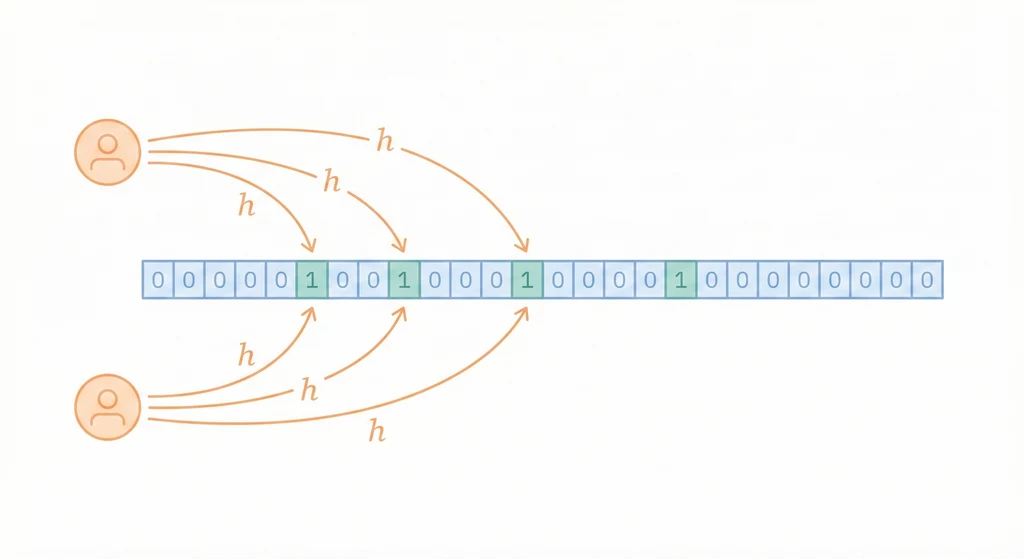
加入 "apple"(3 個 hash function):
hash1("apple") = 2, hash2("apple") = 5, hash3("apple") = 8
[0, 0, 1, 0, 0, 1, 0, 0, 1, 0]
↑ ↑ ↑
加入 "banana":
hash1("banana") = 1, hash2("banana") = 5, hash3("banana") = 7
[0, 1, 1, 0, 0, 1, 0, 1, 1, 0]
↑ 碰撞!5 已經是 1 了
查詢時,算出所有 hash 值,檢查對應的 bit 是不是都是 1:
查 "cherry": hash = 2, 4, 8
bit[2]=1 ✓, bit[4]=0 ✗ → 一定不存在。有一個 0 就能確定。
查 "grape": hash = 1, 5, 8
bit[1]=1 ✓, bit[5]=1 ✓, bit[8]=1 ✓ → 可能存在(但其實是誤判!)
這就是假陽性:所有 bit 恰好都被其他元素設成 1 了。
為什麼能容忍假陽性?
因為大部分場景只需要快速排除「一定不在」的情況。
快取穿透防護:有人狂打一個不存在的 key,每次都穿透快取打到資料庫。用 Bloom Filter 先擋一層——如果它說「不在」,就直接回 404,不查資料庫。偶爾假陽性讓一些不存在的 key 也查了資料庫?沒關係,反正也只是多查一次。
爬蟲 URL 去重:已經爬過的 URL 存進 Bloom Filter。新 URL 先查一下——如果「一定不在」就去爬,如果「可能在」就跳過。漏爬幾個比重爬幾百萬個好太多了。
參數怎麼設?
給定預期元素數 n 和能接受的誤判率 p:
bit array 大小 m = -n × ln(p) / (ln2)²
hash function 數量 k = (m/n) × ln2
| 元素數 | 誤判率 | 需要多少 bit | hash 函數數 |
|---|---|---|---|
| 1,000 | 1% | ~10 KB | 7 |
| 100,000 | 1% | ~120 KB | 7 |
| 100,000 | 0.1% | ~180 KB | 10 |
十萬個元素只需要 120 KB 就能達到 1% 的誤判率。如果你用 HashSet 存十萬個字串,那是好幾 MB。空間效率差距是數量級的。
不能刪除的問題
把某個 bit 從 1 改回 0?不行,因為其他元素可能也 hash 到那個 bit。改了就會讓其他元素產生假陰性——而假陰性是 Bloom Filter 絕對不能有的。
解法:Counting Bloom Filter,把每個 bit 換成計數器。加入 +1,刪除 -1,歸零才真的是 0。代價是空間翻好幾倍。
另一個更現代的選項是 Cuckoo Filter——支援刪除、空間更小、查找更快。如果你的場景需要刪除,直接用 Cuckoo Filter。
雙重 hash 技巧
不用真的寫 k 個 hash function,兩個就夠了:
int hash_i(String item, int i) {
return (hash1(item) + i * hash2(item)) % m;
}用兩個獨立 hash 線性組合出 k 個,數學上證明效果等價。
Bloom Filter 是工程上「不完美但夠用」的典範——用 1% 的錯誤率換來 99% 的空間節省。完美主義者大概會崩潰,但系統工程師會微笑。