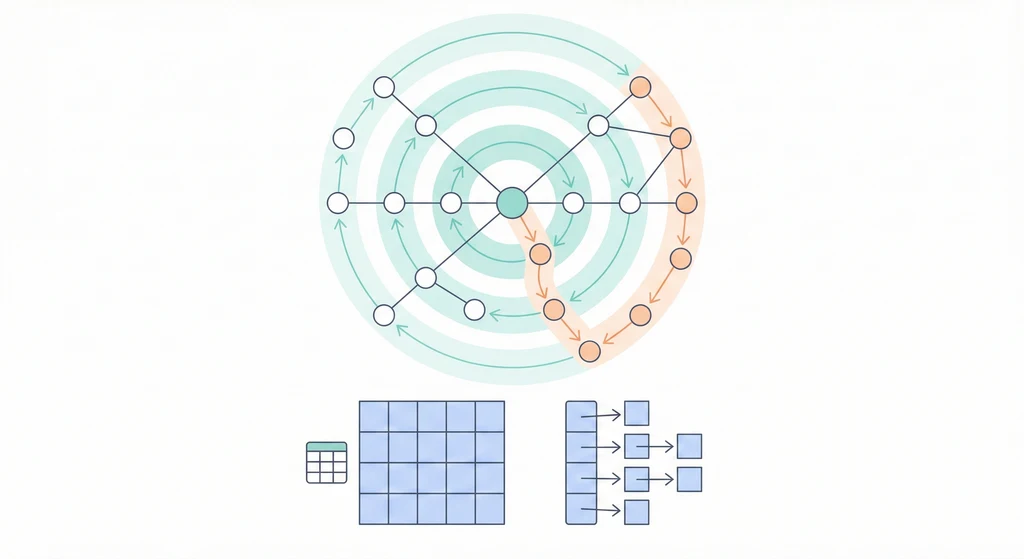
Tree 是特殊的 Graph,Graph 才是描述「關係」的終極資料結構。
先講結論
Graph 由節點和邊組成,能表達任何「東西之間有關係」的場景。兩種存法:鄰接矩陣(查邊快、吃空間)和鄰接表(省空間、查邊慢)。兩種走法:BFS(一層一層擴散,找最短路)和 DFS(一條路走到底,找所有路)。
節點 + 邊 = 圖
1 --- 2
| |
3 --- 4
節點(Vertex):1, 2, 3, 4 邊(Edge):(1,2), (1,3), (2,4), (3,4)
社交網路的好友關係、網頁之間的超連結、城市之間的道路——都是 Graph。Tree 其實是「無環連通圖」的特例。
兩種存法
鄰接矩陣:開一個 V×V 的二維陣列,matrix[i][j] = 1 表示有邊。
1 2 3 4
1 [ 0, 1, 1, 0 ]
2 [ 1, 0, 0, 1 ]
3 [ 1, 0, 0, 1 ]
4 [ 0, 1, 1, 0 ]
查「i 和 j 之間有沒有邊」是 O(1),但空間是 O(V²)。社交網路有十億用戶,你不會想開一個十億乘十億的矩陣。
鄰接表:每個節點存一份鄰居列表。
1 → [2, 3]
2 → [1, 4]
3 → [1, 4]
4 → [2, 3]
空間 O(V + E),查邊要遍歷鄰居列表。但實際上大部分圖都是稀疏的(邊遠少於 V²),所以鄰接表是最常用的。
BFS:水波擴散
BFS 用 Queue,像丟石頭到水裡的漣漪,一圈一圈往外擴。
從 1 開始:
第 1 層: [1]
第 2 層: [2, 3] ← 1 的鄰居
第 3 層: [4] ← 2 和 3 的鄰居(扣掉已訪問的)
Queue<Integer> queue = new LinkedList<>();
queue.add(start);
visited.add(start);
while (!queue.isEmpty()) {
int v = queue.poll();
for (int neighbor : graph.get(v)) {
if (!visited.contains(neighbor)) {
visited.add(neighbor);
queue.add(neighbor);
}
}
}BFS 的關鍵特性:第一次到達某節點的路徑一定是最短路徑(無權圖)。這就是為什麼找最短路要用 BFS 不是 DFS。
DFS:一條路走到黑
DFS 用 Stack(或遞迴),先一直往深處走,走到底了再回頭。
void dfs(int v) {
visited.add(v);
for (int neighbor : graph.get(v)) {
if (!visited.contains(neighbor))
dfs(neighbor);
}
}DFS 適合:拓撲排序、環檢測、找連通分量、回溯法(backtracking)。
BFS vs DFS 選擇
問自己一個問題:「我要找最短的那一條,還是要找所有可能的路?」
找最短 → BFS。探索全部 → DFS。
兩者時間複雜度都是 O(V + E)。
經典圖論問題
| 問題 | 演算法 |
|---|---|
| 最短路徑(無權) | BFS |
| 最短路徑(有權) | Dijkstra |
| 最小生成樹 | Prim / Kruskal |
| 拓撲排序 | DFS |
| 環檢測 | DFS |
| 連通分量 | BFS/DFS 或 Union-Find |
Graph 是資料結構的終極形態——當你的資料不是線性的、不是階層的,而是「任何東西都可能跟任何東西有關」的時候,你需要的就是它。