Heap 不是用來排序的(雖然它可以),它是用來快速找到最大或最小值的。
先講結論
Heap 是一棵完全二元樹,保證根節點是最小(Min-Heap)或最大(Max-Heap)。取極值 O(1),插入和取出 O(log n)。它是 Priority Queue 的標準實作。重點:Heap 不保證整體有序,只保證根是極值。
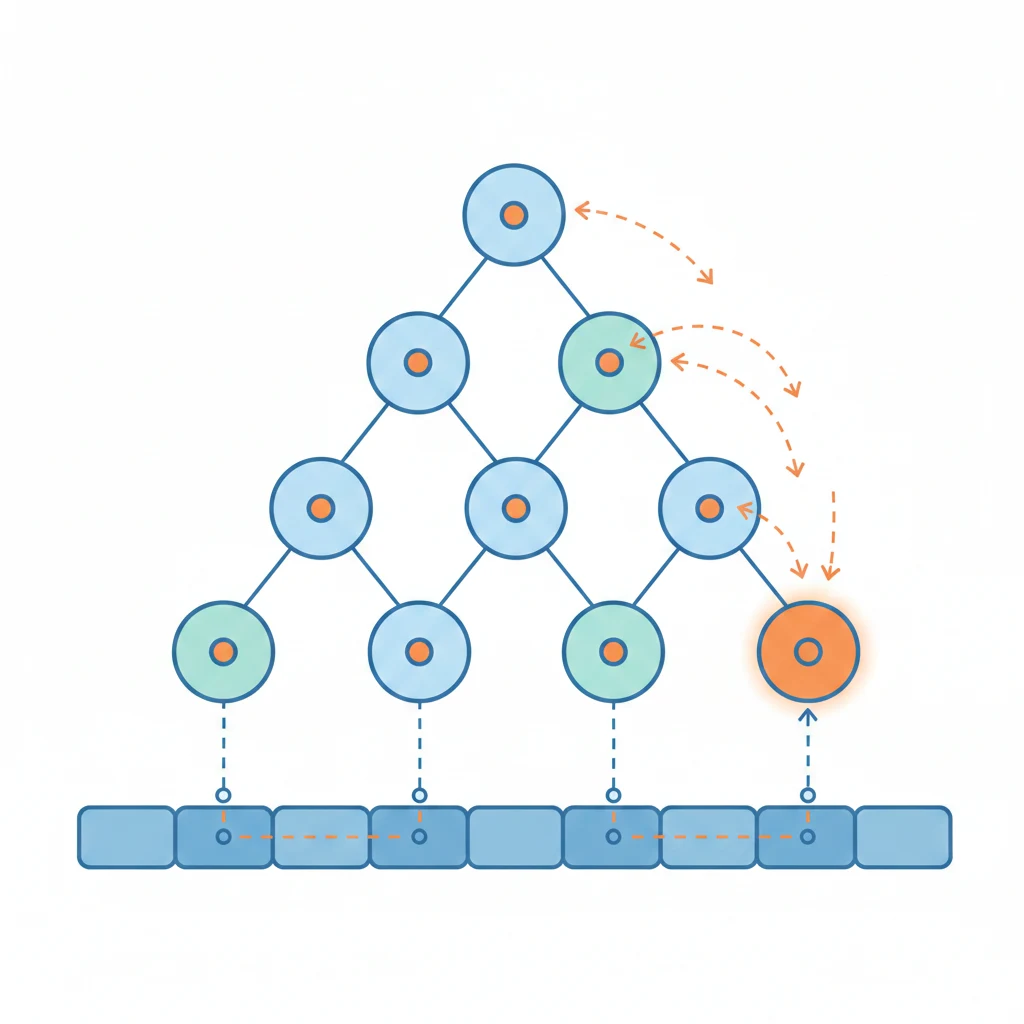
一個陣列就搞定
Heap 雖然概念上是一棵樹,但實際上用陣列存就好。因為它是完全二元樹(每層都填滿,最後一層從左到右填),位置關係可以用公式算:
樹的樣子: 陣列存法:
10 [10, 20, 30, 40, 50]
/ \ 0 1 2 3 4
20 30
/ \
40 50
父節點: (i - 1) / 2
左子節點: 2i + 1
右子節點: 2i + 2
不需要指標、不浪費空間、cache 友善。這是 Heap 實作上最聰明的設計。
插入:從底部上浮
新元素放到陣列最後面(樹的最底層),然後跟父節點比較,比父節點小就交換,一路往上浮。
Min-Heap 插入 15:
[10, 20, 30, 40, 50, 15]
↑ 新加入
15 < 30(父節點)? Yes → 交換
[10, 20, 15, 40, 50, 30]
15 < 10(父節點)? No → 停
結果: [10, 20, 15, 40, 50, 30]
最多浮 log n 層。
取出極值:根拔掉,尾補上,下沉
取出根(最小值),把最後一個元素搬到根的位置,然後跟子節點比較,往下沉。
取出 10,把 50 搬到根:
[50, 20, 30, 40]
50 > min(20, 30)?→ 跟 20 交換
[20, 50, 30, 40]
50 > 40?→ 交換
[20, 40, 30, 50]
同樣最多 log n 層。
Heap vs BST:不同的問題,不同的工具
| Heap | BST | |
|---|---|---|
| 找最小/最大 | O(1) 直接看根 | O(log n) 走到最左/右 |
| 找任意值 | O(n) 得遍歷 | O(log n) |
| 用途 | Priority Queue、Top K | 排序、範圍查詢 |
Heap 只回答一個問題:「現在最大/最小的是誰?」它不關心其他元素的相對順序。如果你需要搜尋特定值,Heap 幫不了你。
Build Heap 是 O(n) 不是 O(n log n)
你可能直覺認為建堆就是把 n 個元素一個一個插入,n × O(log n) = O(n log n)。但有個更聰明的方法:從最後一個非葉節點開始,往前逐一 heapify。
for (int i = n/2 - 1; i >= 0; i--) {
bubbleDown(i);
}為什麼是 O(n)?因為大部分節點在底層,只需要下沉一兩步。數學證明牽涉到等比級數,結論就是所有下沉步數加起來是 O(n)。
經典應用
Top K 問題:找最大的 K 個元素?維護一個大小為 K 的 Min-Heap,遍歷時只保留最大的 K 個。O(n log k),比排序的 O(n log n) 快。
合併 K 個排序陣列:每個陣列的當前最小值丟進 Min-Heap,每次取出全局最小,再從該陣列補一個進來。
Heap Sort:建 Max-Heap,反覆取出最大值放到尾端。O(n log n),in-place。但實務上因為 cache 不友善,通常輸給 Quick Sort。
Heap 的哲學:我不在乎大局的秩序,我只關心誰是第一名。某種程度上,它是資料結構界最務實的存在。