Array 是你最早學會、最常用到、但最容易忽略底層代價的資料結構。
先講結論
Array 的超能力是 O(1) 隨機存取,代價是插入刪除要搬家。如果你的場景是「讀多寫少」,Array 幾乎無敵;如果你整天在中間插來刪去,那你選錯工具了。
連續記憶體:快的根本原因
為什麼 arr[i] 可以 O(1)?因為陣列在記憶體裡是一排連續的格子,每個格子大小固定。只要知道起始位址和 index,一個加法就算出目標位址——不用從頭走,不用查表。
Index: 0 1 2 3 4
+-----+-----+-----+-----+-----+
Data: | 10 | 20 | 30 | 40 | 50 |
+-----+-----+-----+-----+-----+
↑ 起始位址 + (i × 元素大小) = 目標位址
這也是為什麼 CPU cache 特別喜歡陣列——連續記憶體代表高 cache hit rate,遍歷時快得不像話。
讀快、插入刪除痛
| 操作 | 時間 | 為什麼? |
|---|---|---|
讀取 arr[i] | O(1) | 算位址直接跳 |
修改 arr[i] = x | O(1) | 同上 |
| 尾端新增 | O(1)* | 直接放最後 |
| 中間插入 | O(n) | 後面全部往後搬 |
| 中間刪除 | O(n) | 後面全部往前搬 |
| 搜尋(未排序) | O(n) | 最差從頭找到尾 |
*動態陣列平均 O(1),觸發擴容時 O(n)
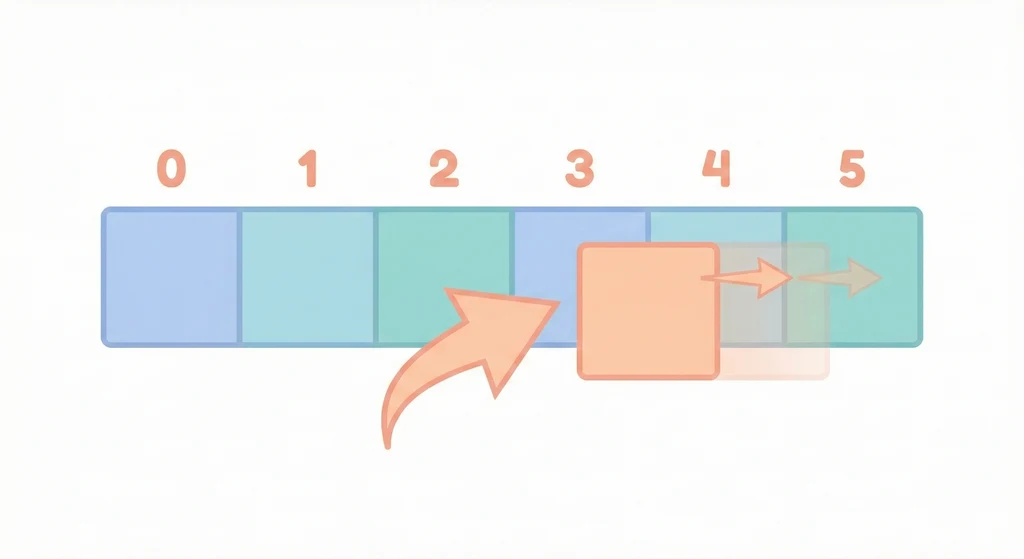
在 index 1 插入 15,代價一目了然:
原本: [10, 20, 30, 40]
Step 1: 把 index 1 之後全部往後搬
[10, __, 20, 30, 40]
Step 2: 塞進去
[10, 15, 20, 30, 40]
搬移量和資料量成正比——這就是 O(n) 的由來。你在一萬筆資料的中間插入一筆,就得搬五千筆。
動態陣列:空間不夠就翻倍
固定大小的陣列太死板,所以有了動態陣列(Java 的 ArrayList、Python 的 list、JS 的 Array)。策略很粗暴但有效:
容量 4,已滿: [10, 20, 30, 40]
要再塞一個?
1. 開一個容量 8 的新陣列
2. 把舊資料全部複製過去
3. 放入新元素
結果: [10, 20, 30, 40, 50, __, __, __]
擴容那一次是 O(n),但平均下來每次新增還是 O(1)——這叫 amortized O(1)。你可以想成「偶爾搬一次大家,但大部分時候免費」。
不過有個反直覺的點:如果你事先知道會放 10 萬筆資料,先 new ArrayList<>(100000) 預設容量,可以完全避免擴容的搬移成本。很多人不知道這件事,然後在 profile 裡看到 Arrays.copyOf 吃掉效能還很困惑。
什麼時候不該用 Array?
- 頻繁在中間插入刪除 → 考慮 Linked List
- 資料量完全無法預估且變動劇烈 → 考慮 Linked List 或其他動態結構
- 需要 key-value 查找 → 你要的是 Hash Table
反過來說,如果你需要隨機存取、遍歷、或資料量大致固定,Array 就是最佳解。別什麼都用 Map,拜託。
Array 是資料結構界的白飯——不起眼,但少了它什麼菜都配不起來。