上一篇講了五個基礎排序。這篇講的是「特殊場景的排序」——當你的資料有特殊性質時,可以比 O(n log n) 更快。以及 Tim Sort,你每天都在用但可能不知道的排序演算法。
先講結論
比較排序的理論下界是 O(n log n),沒辦法更快了。但如果你的資料是整數、值域不大、或均勻分佈,非比較排序可以做到 O(n)。
| 演算法 | 時間 | 空間 | 穩定 | 適用 |
|---|---|---|---|---|
| Heap Sort | O(n log n) | O(1) | 否 | 記憶體受限 |
| Counting Sort | O(n + k) | O(k) | 是 | 整數,值域小 |
| Radix Sort | O(d(n+k)) | O(n+k) | 是 | 整數,位數固定 |
| Bucket Sort | O(n + k) | O(n) | 是 | 均勻分佈 |
| Shell Sort | O(n^1.3) | O(1) | 否 | 中等規模 |
| Tim Sort | O(n log n) | O(n) | 是 | 通用(內建排序) |
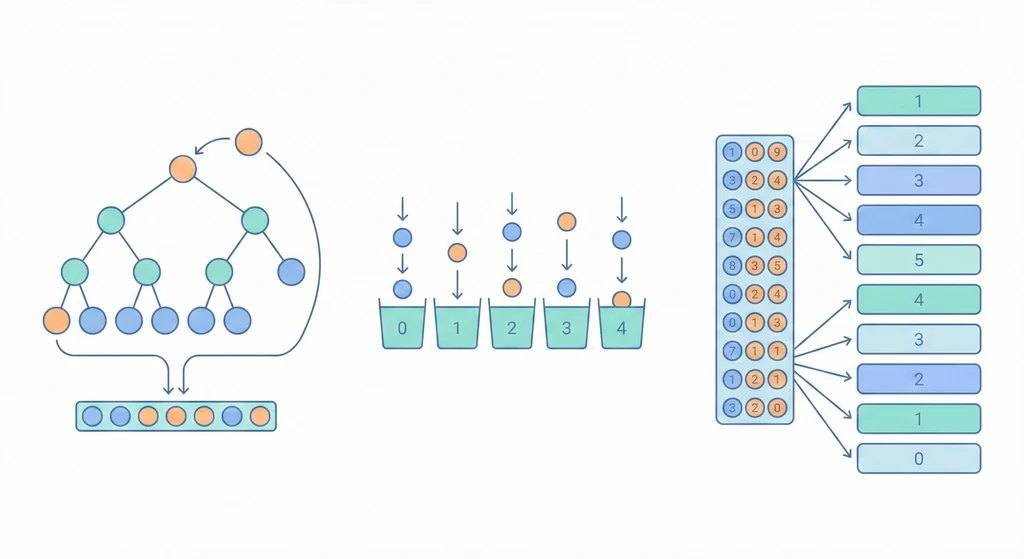
Heap Sort:空間最省的 O(n log n)
利用 max heap 的性質:根節點永遠最大。每次取出根(最大值)放到陣列尾端,再調整堆。
void heapSort(int[] arr) {
int n = arr.length;
for (int i = n/2-1; i >= 0; i--)
heapify(arr, n, i); // 建堆 O(n)
for (int i = n-1; i > 0; i--) {
swap(arr, 0, i); // 最大值放後面
heapify(arr, i, 0); // 調整 O(log n)
}
}O(1) 額外空間,但 cache locality 差(heap 的存取模式跳來跳去),所以實務上比 Quick Sort 慢。什麼時候用?記憶體極度受限或需要保證最差 O(n log n)(Quick Sort 最差是 O(n²))。
Counting Sort:不比較,純計數
如果值域是 0~k,開一個大小 k 的陣列統計每個值出現幾次,然後按順序輸出。
[4, 2, 2, 8, 3, 3, 1]
count: [0, 1, 2, 2, 1, 0, 0, 0, 1]
結果: [1, 2, 2, 3, 3, 4, 8]
O(n + k)。但如果值域很大(比如排序身分證字號),開不了那麼大的陣列。
Radix Sort:按位數排
從低位到高位,每一位用 Counting Sort。
[170, 45, 75, 90, 802, 24, 2, 66]
按個位: [170, 90, 802, 2, 24, 45, 75, 66]
按十位: [802, 2, 24, 45, 66, 170, 75, 90]
按百位: [2, 24, 45, 66, 75, 90, 170, 802]
O(d × (n + k)),d 是位數。適合整數且位數固定的場景。
Bucket Sort:分桶再排
把數據分到幾個桶裡,每個桶內部排序,再合併。
如果數據均勻分佈,每個桶裡的元素很少,桶內排序幾乎是 O(1),整體接近 O(n)。不均勻的話就退化成 O(n²)。
Tim Sort:你一直在用的排序
Python 的 sort() 和 Java 的 Arrays.sort()(Object 版)用的就是 Tim Sort。
核心想法:現實世界的資料很少是完全亂序的,通常有一些「已排序的片段」。Tim Sort 先找出這些片段(run),小片段用 Insertion Sort,再用 Merge Sort 合併。
- 近乎有序?O(n)
- 一般情況?O(n log n)
- 穩定?是
所以你不需要自己挑排序演算法——語言內建的已經幫你選了 Tim Sort。除非你有特殊需求(整數值域小 → Counting Sort、記憶體受限 → Heap Sort),否則直接 .sort() 就好。
怎麼選?
你的資料是什麼?
├─ 整數,值域小 → Counting Sort
├─ 整數,位數固定 → Radix Sort
├─ 浮點數,均勻分佈 → Bucket Sort
└─ 通用資料
├─ 記憶體受限 → Heap Sort
├─ 幾乎有序 → Insertion Sort / Tim Sort
└─ 一般情況 → Quick Sort / 直接 .sort()
最好的排序演算法是什麼?答:你語言內建的那個。Tim Sort 已經幫你做了所有你該做的最佳化。除非你在面試,否則請直接用 .sort()。